2 GPU 并行加速算法
GPU 具有高度并行的多流水线架构,使其非常适宜于FDTD 加速运算。与CPU 运算的多次循环逐网格迭代更新方式不同,GPU 可以实现多网格的同时迭代更新,配合GPU 的线程集指令执行机制,可以高效地利用流水线资源,隐藏流处理器与设备内存间的场量读写延时,从而实现FDTD 运算加速。
2.1 GPU 函数的并行
2.1.1 数据并行优化
OpenCL 支持按数据并行的编程模型和按任务并行的编程模型。数据并行是一种普遍意义上的并行方式,在程序中,常有一些循环操作,如果在循环的内部各个计算过程之间不存在相关性,则可以转换成并行循环,即数据并行。
由 FDTD 中电磁场的时间推进计算公式可知,FDTD方法中每一网格点的电磁场值只与紧邻的网格点上电磁场值及本网格点上一时间步的电磁场值有关,而与远端网格点的 场值无直接关系。也就是说,时间步长上的迭代过程是相互关联、相互影响的,迭代需要上迭代的计算结果,故迭代之间不宜实现并行化。而在迭代内 部,电场和磁场的计算仅需要前一时刻的计算结果,各个计算过程之间没有影响,因此FDTD 并行化适合于用空间分区、时间分段的方式来分配运算任务,可以使用数据并行编程模型实现并行计算。
在 GPU 上实现FDTD 加速算法思路为:将每个数据元素映射到每个线程,就是将FDTD 三维网格划分成为一个二维工作组,然后每个工作组中包含一维的工作项,通过工作组的id(groupID)和工作项的id(localID)来索引工作项 在缓冲对象中的位置,用一个工作项来计算一个场值,如图3 所示。这样,在一个工作组中的多个工作项可以相互协作、共享计算单元的内存空间、同步、共享结果以节省计算,同时每个工作项当中的工作组和周围的两个 Yee 元胞进行数据交换,因此可以提供很快的数据访问,大大节省设备内存带宽的消耗。

此外,由于 OpenCL 的缓冲对象只支持存储一维元素集合,所以要把CPU 算法中相应的三维数组和二维数组转换为一维数组(包括电场参数和磁场参数)。
2.1.2 局部存储器和内建矢量使用
SAR_EH_CPX_Kernel 对一个一维缓冲对象进行了更新操作。CPU 代码中每次循环更新12 个变量,意味着每个计算单元需要读/写12 次全局内存。我们设计的OpenCL并行方案访存通过OpenCL 内建矢量,每次访存循环读入3个cl_float4 变量到速度更快的局部存储器中。将逐单元的访存改为逐数据块访存,如图4 所示,同时利用了速度与寄存器相当的局部存储器。分析代码发现,对规模为M*N*K 的三维数据块减少了K*8 次全局内存的读/写操作。

此外,对CPU 上耗时长、计算逻辑也比较简单的对E 和H 进行修正计算的函数,线程和数据之间是一一映射的对应关系,为了提高访存效率,在kernel 内部也使用了内建矢量数据类型对访存进行了优化。
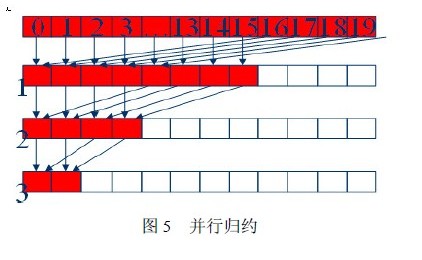
3.1.3 并行归约
snefar 函数中对四个变量进行求和操作,在OpenCL实现了两个kernel 对该函数进行了并行归约的优化。由于实际求和的个数不是2 的幂,所以设置工作项为2 的幂次方后,在Kernel 中首先初始化局部内存为0,然后将数据从全局内存顺序读入局部存储器中,在局部存储器进行运算。实现归约求和的主要代码如下:
for(unsigned int s = get_local_size(0)/ 2; s > 0; s 》= 1)
{
if(tx < s)
sdata[tx] += sdata[tx + s];
barrier(CLK_LOCAL_MEM_FENCE);
}
其中 tx 为get_local_id(0),为工作项在工作组中的一维下标。归约如图5 所示。此并行归约可以进行循环展开,实现进一步的优化。
2.2 多GPU 系统的并行算法
2.2.1 区域分割与负载均衡
我们使用 MPI 进行数据通信和调度,实现多GPU 核并行算法。步就是要对数据块进行区域分割,建立拓扑结构。
测试所用的 FDTD 数据块为三维数据,故区域分割方式主要有三种:一维分割、二维分割和三维分割。观察代码发现,如果进行一维分割,无论沿XYZ 哪个方向进行,数据块与数据块之间的通信量极少,只涉及边界交换,故为代码移植简单起见,我们实现的MPI 是基于一维沿X 方向进行数据分割。
负载平衡是区域分割的一个重要原则,我们实现的代码中首先获得节点中所有具备计算能力的GPU 核,给每个核分配固定的id,根据id 分配相同大小数据块,使得具有相同计算能力的处理器获得相同的工作量。对于update_E_PML 和update_H_PML 这两个计算边界而言,由于我们沿X 方向进行分割,在计算个节点和一个节点需要更新整个X 平面,因此这两个函数的计算负载没有实现均衡。
2.2.2 数据通信
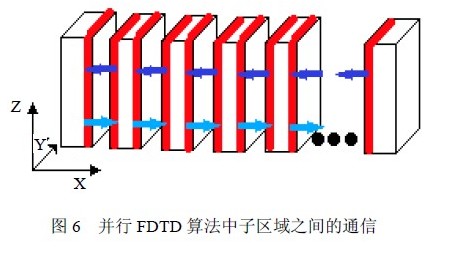
多 GPU 核FDTD 算法另一个重要问题就是数据通信,也是MPI 存在的。在FDTD 计算区域分割成多个子区域后,各个子区域内部的场分量按照原有的迭代公式进行计算,而子区域界面上的场分量的迭代计算就需要相邻子区域上相应的场分量,此 时便需要相邻子区域之间的数据通信。
简单来说,对于我们实现的三维FDTD多GPU核并行,每个非边界上的子区域都需要与左、右方向上的相邻子区域进行数据交换,如图6 所示。在每一轮迭代中,这种边界交换一共需要四次,两次在更新E 和H 分量前,另外两次在更新E 和H 的边界前。
相关资料:
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。