与传统小波相比较而言,提升小波变换不仅具有多分辨率的优点,而且简化了运算,便于硬件实现,因此在数字图像编码领域中得到了广泛的应用。在新的图像压缩标准JPEG2000中(J0int Photographic Experts Group,它是一个在国际标准组织(ISO)下从事静态图像压缩标准制定的委员会),采用9/7、5/3提升小波变换作为编码算法,其中5/3小波变换是一种可逆的整数变换,可以实现无损或有损的图像压缩。在通用的DSP芯片上实现该算法具有很好的可扩展性、可升级性与易维护性。用这种方式灵活性强,并且完满足各种处理需求。
1 提升算法
提升算法[1]是由Sweldens等在Mallat算法的基础上提出的,也称为第二代小波变换。与Mallat算法相比,提升算法不依赖傅立叶变换,降低了计算量和复杂度,运行效率相应提高。由于具有整数变换及耗费存储单元少的特点,提升算法很适合于在定点DSP上实现。提升算法的主要特征是把高通和低通小波滤波器分解成一列小型滤波器,进而转化为一列上下三角矩阵。
小波提升算法的基本思想是通过基本小波逐步构建出一个具有更加良好性质的新小波,其分为三个主要阶段:分解(split)、预测(predict)和更新(update)。
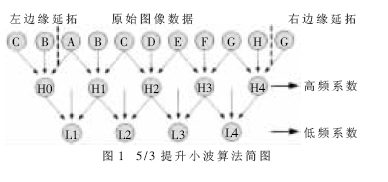
首先按照对原信号进行对称延拓得到新的x(n)。
分解是将数据列分成为两个小的子集,按照数据的奇偶序号分为为偶数序列x(2n)和奇数序列x(2n+1)二个部分,奇偶分量被认为是惰性小波,因为这个过程没有去掉数据的相关性;
在预测阶段,主要是消除步分解留下的冗余,给出更紧凑的数据表示,保持偶数序列不变,利用偶数序列来预测奇数序列,得到的预测误差为变换的高频分量:H(n)=x(2n+1)-{[x(2n)+x(2n+2)]》1};
更新是由预测误差更新偶数序列,得到变换的低频分量: L(n)=x(2n)+{[H(n)+H(n-1)+2]》2},更新的目的在于保持信号的某些全局特性不变,如均值。
计算过程如图1所示。
2 基于DM642的优化策略
2.1 DM642的两级CACHE结构
DM642是一款专门面向多媒体处理领域应用的处理器,是构建多媒体通信系统的良好平台,已被国内外视频应用从业者广泛接受和采用。它采用C64xDSP内核,片内RAM采用两级CACHE结构[4][5],分为L1P、L1D和L2。L1距离DSP核近,数据访问速度快,只能作为不能寻址的CACHE被CPU访问,由相互独立的LIP和LID组成,LIPCache大小为16kB,直接映射,每行大小为32B;LID Cache大小16kB,2路映射,每行大小为64B,访问周期与CPU周期一致;L2可作为SRAM映射到存储空间使用,也可整体作为第二级Cache,或是作为二者按比例的一种组合混合使用。L2作为SRAM使用时,即是DM642的片内内存,从整个系统地址空间的起始地址0x00000000开始编址,当作为Cache使用时,4路映射,每行大小为128B,容量在32-56kB 之间。
DM642有256kbit/s的片内内存,对于直接处理图像数据还是很有限的。如MPEG-4算法一般至少要存储当前待编码帧数据和上一帧的重建帧数据,一帧YUV4∶2∶0格式CIF图像的数据约有150kB,256kB,内存对于CIF 图像就不够了。对于DM642,数据如果放在板卡上的片外内存中, 数据的处理速度会大大降低,这是因为DSP对于片外数据的运算要慢得多。我们一般采取的方案是对图像以宏块为单位处理,只将运算时该宏块需要的数据导入片内, 其他数据留在片外,这样的数据量就足够放在片内了。
2.2 改进的算法结构
传统的小波变换都是对整幅图像作变换,首先对每一行作变换,然后再对每一列作变换。若采用这种方式在DSP上实现该算法时效率是很低的。这是因为DSP的L1D很小,只有16KB,并不能完整的缓存整幅图像,因此原始图像数据通常保存在速度较低的外部存储器上。这样CPU从L1D每读取一行数据时将必然会产生缺失,而大量缺失则会严重阻塞CPU的运行速度,从而延长程序的执行时间。为了解决这一难题,减少缺失的发生,我们必须改进传统的变换方式。将原来对整幅图像的变换改为分块的变换,即每次从图像中取出一小块,先后进行行、列变换后再按照一定的规则保存到系数缓存中,如图2所示。
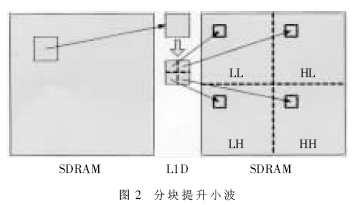
在这种方法中,SDRAM中的一个数据块首先传输到L2中,然后取到L1D中进行水平方向的提升,再对该块进行垂直方向的提升。这样,由于垂直提升所需的数据都在L1D中,因此避免了此处数据缓存缺失的产生,从而使总的缺失数大大降低。
2.3 数据传输
(1)SDRAM与L2间的数据传输
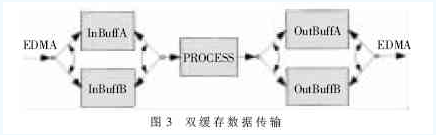
由于EDMA[6][7]数据传输与CPU运行相互独立,因此在L2中开辟两块缓存:EDMA在CPU处理InBuffA的同时将下一块数据传输到InBuffB,解决了CPU读取低速设备SDRAM引起的时延,如图3所示。
(2)L2与L1D间的数据传输
CPU首先访问级CACHE中的程序和数据,如果没有命中则访问第二级CACHE(如果配置L2的一部分为CACHE),若还没有命中就要访问外部存储空间。在这个过程中,CPU一直处于阻塞状态,直至读取的数据有效。所以,在对L2中的数据块进行水平提升时,CPU读取每一行都会产生缺失。针对这种情况,TMS320C64x系列DSP为L1D提供了一种高速缓存缺失处理的流水处理机制。若连续多次未命中,CPU等待时间就会重叠,总体上减少了平均缺失造成的CPU阻塞时间。
因此,在CPU对数据进行水平提升前,利用缺失流水技术,将当前数据块全部读取到L1D中,随后再对该数据块进行水平提升,则不会再发生缺失,并可提高运算速度。
CPU和程序高速缓存L1P、数据高速缓存L1D直接相连,第二级缓存由程序空间和数据空间共享,可以设置成L2 Cache和片内SRAM。EDMA控制器负责片内L2存储器与外设之间的数据传输,可以提供超过2GB/s的数据传输宽带。两级缓存结构和EDMA基本决定了H264视频编码器内图像数据传输的架构。
(3)图像数据传输流程
两级Cache结构显着提高了DSP的基本性能,解决了低速片外数据存取和高速CPU数据处理之间的矛盾。当CPU中编码程序要访问图像数据时,查看片内内存L1D和L2;若片内内存没有缓存该数据,则通过EDMA访问外部SDRAM,把数据从外部SDRAM拷贝到L2缓存区,再从L2缓存区拷贝到L1D,由CPU取得。
如果CPU当前访问的图像数据位于低速SDRAM,则EDMA把其后面地址的几个相邻数据也一并取到Cache中。当CPU接着访问相邻数据时,可直接从Cache中读取,而不需再次访问片外SDRAM,从而提高Cache的命中率。
大量的图像数据传输和复杂的算法处理一直是实时视频编码系统的速度瓶颈问题。结合DM642处理器的Cache结构和EDMA功能,有效设置和利用EDMA控制器,可以解决H.264视频编码器中存储器和外设之间的图像数据纯属速度问题,从而能够大大减轻CPU的负担,并提高H.264编码系统的实时性。实验证明,灵活使用EDMA不仅能够提高图像数据传输效率,而且可以充分发挥DM642的高速性能。
2.4 L1P与L1D性能优化
L1D是两路成组相关,每组容量大小8KB,总容量大小为16KB。CPU处理的数据容量大小不应超过8KB,并且所有的原始数据都是连续存储在同一CACHE组中的;程序的中间过程数据保留在预分配的另一个CACHE组中。
数据读取到L1D之后,首先由8位扩展成16位,然后对这些数据进行水平提升,只要这些数据能保留在L1D中,随后进行的垂直提升就可以完全避免缺失。因此,数据块的大小是由中间过程数据决定的,所有中间过程数据加起来不能超过8KB,选取数据块是32×32。
当多个函数映射到L1P的同一个CACHE行时就会引起冲突缺失,所以必须合理的放置这些函数。由上面我们得知实现提升的全部函数加起来总容量大小不超过16KB,因此,如果能将这些函数安排在一个连续的存储空间内,就可以完全的避免由于冲突而引起的L1P缺失。我们可以在cmd[8]文件的SECTIONS中添加一个GROUP,然后将频繁调用的函数全部放到GROUP中(以下为代码示例):
SECTIONS
{
GROUP > ISRAM
{
.text:_horz
.text:_vert
.text:_IMG_pix_pand
…
}…}
2.5 程序优化
由前面的分析可知,对图像进行提升小波变换时,需要对其四个边界进行延拓。延拓方式采用图1所示的对称延拓(对称延拓有两种方式,方式1是令在支撑区以外,以边界点为中心对称重复,方式2是令在支撑区以外,以边界为中心对称重复),其中左边与上边需要多延拓一个点。而对图像中的一个块进行提升变换时,其延拓的应该是与该块相邻的四个块数据的边界数据,如图4所示。
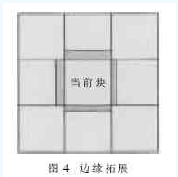
边界延拓的主要用途是计算高频系数。数据分析发现,水平提升时,当前数据库块每一行的一个高频系数与下一块在该行的个高频系数是相同的,所以只要把当前块的这些系数全部保存起来,在对下一块进行水平提升时个高频系数就不需要再进行计算,因此也就不需要再对其左边界进行延拓了。实验证明,垂直提升也是同样的。在程序设计中添加两个数组,一个数组存放当前块的每一行的一个高频系数,另一个数组存放当前块的每一列的一个高频系数。采用这种方法就可以大大的降低程序的复杂度,从而提高程序执行效率,进一步的减少缺失的发生。
像素扩展函数pix_pand[9]是采用TI的IMGLIB算法库。水平提升与垂直提升函数均由作者用线性汇编语言编写,充分利用64x系列DSP的半字处理指令,并采用半字打包技术,限度地提高程序的执行效率。
水平提升时,将每行的数据重新排序,变成如图5所示的结构。

使用C64x的ADD2、SHR2和SUB2等半字处理指令,将如下的两个运算并行执行:
H(1)=B-[(A+C)》1]
H(2)=D-[(C+E)》1]
垂直提升时则可以安排多列的计算并行执行,如图6所示。
H1(1)=B1-[(A1+C1)》1]
H2(1)=B2-[(A2+C2)》1]
3 仿真结果
表1列出了CPU读取L1D时所产生的缺失数。其中,水平方向的缺失不可避免。由于要对数据块的右侧和底部进行边界延拓,所以在水平方向的缺失数比传统方法略高;而在垂直方向上,该算法完全避免了缺失的发生。
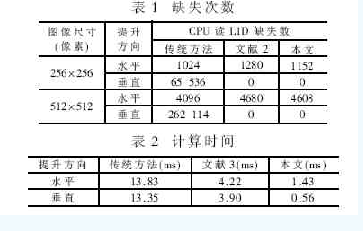
表2列出了几种方法的性能计算。由于本文采用了多种优化技术,运算速度因此而提高了4~10倍。
本文介绍了5/3提升小波变换及其在DM642上的实现。为了提高其性能而提出了多项优化技术,试验证明优化方法比常规方法有着更高的效率。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。