什么是
CPU硬件缓存?
CPU 硬件缓存是一种较小的
内存,靠近处理器,用于存储近引用的数据或指令,以便在再次需要时可以快速检索它们。通过减少访问速度较慢的主内存的昂贵读写操作,缓存对 CPU 的性能产生巨大影响。几乎所有现代处理器都采用某种形式的缓存。
个缓存位于片外或外部。这些很快就被通常由 SRAM 制成的片上高速缓存所取代。为了进一步提高性能,这些片上缓存被分为指令和数据分区。
图 1 显示了分区示例。
图 1. Intel 80486 使用通用高速缓存,而其后继产品 Pentium P5 使用分区高速缓存(
总线宽度已省略)
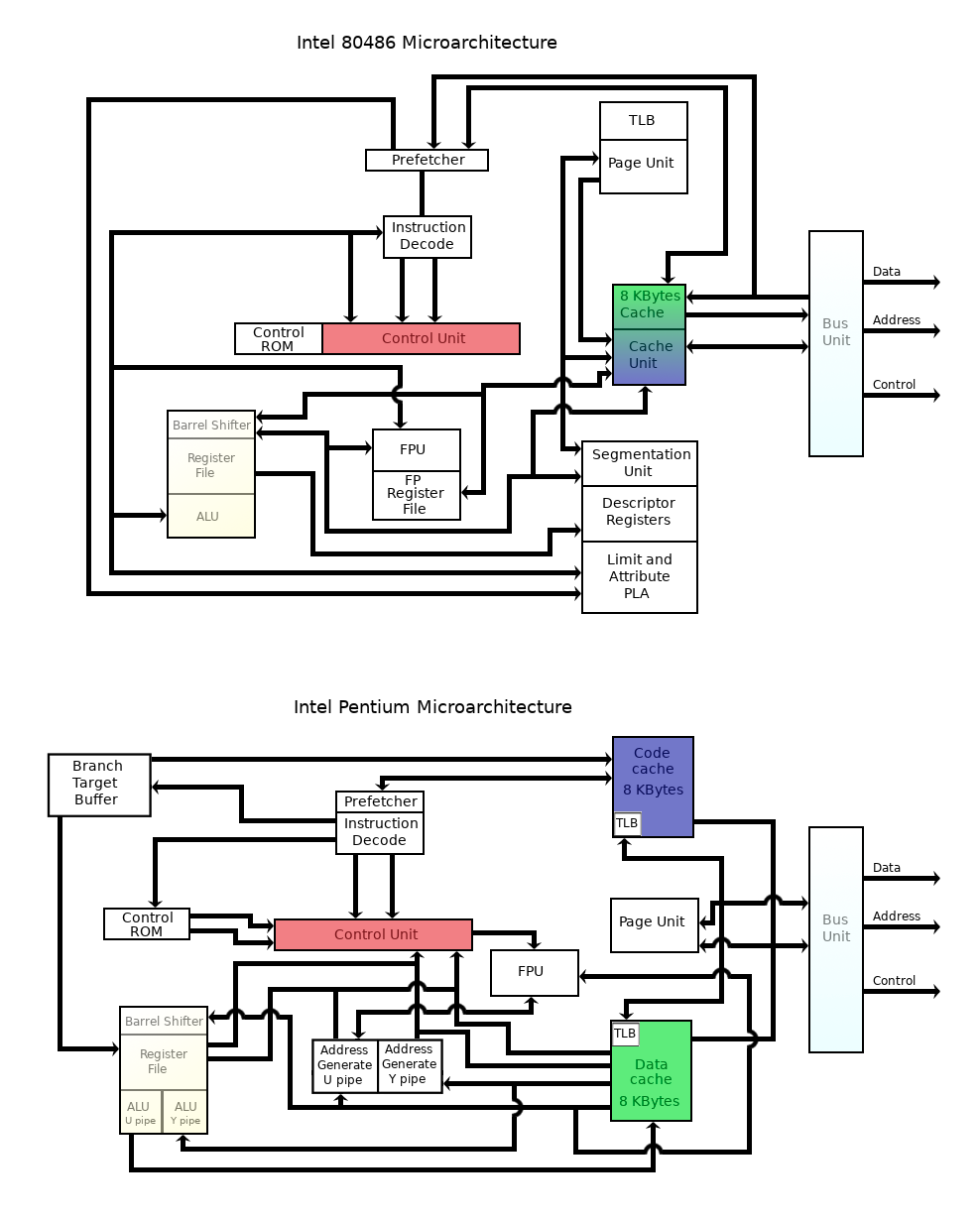
高速缓存分区导致了多级高速缓存层次结构的诞生,其中处理器将拥有自己的小型专用高速缓存 (L1),位于较大的共享高速缓存 (L2) 之上,某些处理器还包括第三级高速缓存 (L3) 和有时是第四个(L4)。
位置(又名缓存如何工作?)
为什么缓存会起作用?缓存通过引用局部性原则进行工作。引用局部性是指处理器在运行应用程序时访问相同内存位置的趋势。由于这些内存访问是可预测的,因此可以通过缓存来利用它们。
局部性通常分为两个子集——时间局部性和空间局部性——有时还有第三个子集,称为算法局部性。
时间局部性
时间局部性是指在短时间内重用特定数据项。这依赖于这样一个事实:在处理器上运行的程序倾向于在短时间内使用相同的变量和数据结构。从主内存中获取项目并将其存储在缓存中后,对该数据的任何后续调用都可以更快地完成。
空间局部性
空间局部性是指即将需要的数据项驻留在当前需要的数据项附近或邻近的存储位置的趋势。这可能是程序员或编译器在内存中对项目进行聚类的结果。
例如,使用数组(一种数据结构)的应用程序会将数组的元素存储在相邻的内存位置中。通过缓存当前正在使用的数据项旁边的数据项,处理器可以在必要时快速访问那些相邻的项。
算法局部性
一种不太常讨论的局部性类型是算法局部性。算法局部性是应用程序对相关数据项执行操作的趋势,尽管这些数据项不是在很短的时间内,并且这些项在内存中彼此并不靠近。
使用链表(另一种类型的数据结构)的应用程序可能会表现出这种行为。这种类型的局部性可能出现在图形处理或迭代模拟中。
逻辑缓存组织
缓存存储和检索数据的方式和位置取决于缓存的组织方式。这称为缓存的逻辑组织。确定存储的内容是由缓存中内置的管理启发式方法控制的,但它也很大程度上受到逻辑组织的影响。因此,缓存的布局对其性能起着巨大的作用。
组织缓存的主要方式有以下三种:
完全联想
直接映射
设置关联
缓存块
当CPU需要访问主存中的某个项目时,它使用地址来定位该项目。CPU 硬件缓存通常透明地工作,这意味着程序员无需以任何方式确认缓存。因此,用于访问内存的地址首先由高速缓存处理。该地址用于标识数据项是否位于高速缓存中。
术语“缓存命中”表示在缓存中找到了该数据项,“缓存未命中”表示未在缓存中找到。
高速缓存被组织成称为高速缓存块的数据组。每个地址被划分为多个位字段,以便可以识别正确的缓存块。这些字段是缓存标记、集合编号和字节偏移量。图 2 显示了将地址拆分为缓存可以解释的字段的情况。

图 2. 寻址缓存块
当 CPU 高速缓存获得一个地址时,它会将该地址分解为必要的字段并开始检查其高速缓存条目。一个缓存条目由缓存标签(这里是标记标签)和缓存块(标记数据)组成。
缓存标签是一个标识符,表示正在引用哪个缓存块。
缓存块是存储在该标签处的实际数据,代表主
存储器中的项目块。为了获取该块内的各个单词,需要使用偏移量。
直接映射
在直接映射高速缓存中,高速缓存条目被组织成多个集合。地址中的集合编号用于索引每组条目。一旦识别出该组,就会比较缓存标签。如果它们匹配,则这是缓存命中并输出指定的数据。
理解直接映射缓存的关键是每个集合只有一个缓存条目。这使得直接映射缓存速度极快,同时消耗少的电量。

图3 . 直接映射缓存
由于每一组只能包含一个条目,因此直接映射缓存确实具有更高的争用率,这意味着多个数据项将希望存储在同一位置。这会导致缓存未命中。解决此问题的一种方法是使用完全关联的缓存。
完全关联
全关联缓存与直接映射缓存相反。与包含单个条目的多个集合不同,全关联高速缓存具有全部包含在单个集合中的多个高速缓存条目。因此,该集合编号不再提供任何信息并且不再被使用。相反,当缓存处理内存地址时,会检查每个缓存条目是否有匹配的标签。如果找到,则使用字节偏移量输出缓存块内的正确数据。
检查每个缓存条目使得全关联缓存比直接映射缓存消耗更多的电量。通过使用一组关联高速缓存来找到功耗和较高争用率之间的平衡。

图 4. 全关联缓存
集合关联
一组关联缓存提供了两全其美的优点。它由多个集合组成,每个集合有多个缓存条目。它是如何工作的?首先,集合编号允许缓存跳转到适当的条目集合。接下来,在每组条目中搜索匹配的标签。如果找到,则使用字节偏移量来输出请求的数据。这种方法允许缓存提供功耗和争用率的优化平衡。
图 5 显示了 4 路组关联高速缓存。之所以称为 4 路,是因为每组多可以包含四个缓存条目。如果每个集合只能容纳两个缓存条目,那么它将是 2-way。因此,直接映射缓存实际上只是 1 路组关联缓存,而全关联缓存是单组 m 路组关联缓存,其中 m 是缓存条目的数量。

图 5. 设置关联缓存
管理启发法
一旦确定了缓存的逻辑组织,就需要确定一组管理启发式方法。管理启发法只是一组确定缓存如何履行其职责的规则。这些通常在位于高速缓存之上的高速缓存控制器中实现,并充当高速缓存和 CPU 之间的
接口。缓存管理启发式可以分为两个不同的类别:内容管理和一致性管理。
内容管理
内容管理启发式正如其听起来的那样。它们是一组规则,用于确定何时缓存以及缓存什么内容。这些启发式方法识别已从内存请求的重要项目并将这些项目复制到缓存中。内容启发式的两个示例是预取被认为重要或即将使用的数据项,以及决定当缓存集已满或接近容量时替换哪些项的替换策略。