音频工程师面临的挑战是设计设备,提供更好的音频保真度,支持更多音频通道,处理更高的采样率和位深度,同时保持紧张的实时处理预算。
在许多音频应用中,系统性能的主要瓶颈是音频数据的高效移动。多年来,数字信号处理器 (DSP) 架构引入了各种创新,从 DSP 内核卸载了许多 I/O 或数据移动任务,使其能够专注于信号处理任务。
直接
内存访问 (DMA) 引擎是当今大多数高性能 DSP 的关键组件。DSP 可以配置 DMA 引擎来访问片上和片外资源,并促进它们之间的传输,而不必显式访问
存储器或外设。这些 DMA 传输可以与关键 DSP 内核处理并行执行,以获得性能。
标准 DMA 引擎非常适合传统的一维和二维算法处理,例如块复制和基本数据排序。但是,许多音频算法需要更复杂的数据传输。延迟线就是一个例子,它由前一个时间点的音频样本组成,用于创建所需的音频效果(例如回声)。传统的 DMA 性能对于管理延迟线来说并不是的,需要对 DMA 架构进行创新,以有效地处理所需的音频算法。
是否需要DMA加速?
这个问题的答案是肯定的,原因有两个。首先,许多高性能 DSP 引擎中的 DMA 通道数量限制了 (pro) 音频应用。其次,由于对高质量音频的需求,音频应用中的传统DMA通常需要更多的CPU参与

图1。音频应用框图
上面的框图描述了典型音频应用中的数据流。每个效果获取前一个效果的输出,处理数据,并将其输出转发到数据处理链中的下一个效果(例如,Phaser 效果的输出被输入到 Delay 效果,Delay 效果的输出被发送到混响) 。
上图所示的数字音频效果依赖于延迟线来实现。在描述完整的效果系统时,需要多个延迟线。改变设计中使用的延迟长度会改变音频效果的质量。
延迟线是线性时不变系统,其输出信号是延迟了 x 个样本的输入信号的副本。在 DSP 上实现延迟线的有效方法是使用循环
缓冲器。循环缓冲区存储在线性存储器的专用部分中;当缓冲区被填满时,新的数据被写入,从缓冲区的开头开始。
循环缓冲区数据由一个进程写入,由另一个进程读取,这需要单独的读写指针。读写指针不允许交叉,这样未读数据就不会被新数据覆盖。循环缓冲区的大小由效果所需的延迟决定。在本文中,先进先出 (FIFO) 和循环缓冲区名称可以互换使用。
当使用传统的 DMA 引擎在基于延迟的音频效果中移动数据时,会为信号处理链中的每个效果分配一个单独的循环缓冲区。馈送到特定音频效果的输入数据存储在分配给该效果的循环缓冲区中。下面的框图显示了更详细的数据流。在下面图 2 的框图中,循环缓冲区由环表示。使用循环缓冲区的环形表示,因为它显示分配给循环缓冲区的线性地址空间的包装。当指针通过循环缓冲区前进时,地址将增加,直到遇到回绕条件,导致指针重置到内存地址或循环缓冲区的起始点。
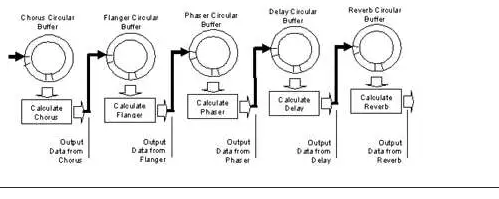
图2. 使用传统DMA引擎时的Pro音频应用数据流框图
为了产生不同的延迟,DMA 必须从延迟线内的不同位置检索延迟数据。如果使用块处理,则会检索一组数据而不是仅一个样本。
传统的 DMA 引擎通常允许程序员指定几个完整描述所需传输的参数。通常,这些参数是源地址、目标地址、源和目标的索引以及传输计数。每次 DMA 传输将需要一个典型 DMA 总体功能的通道。
在上面的框图中,有五个循环缓冲区。传统的 DMA 引擎必须经过编程才能将数据移入和移出每个缓冲区。在上面所示的应用中,处理一个数据块至少需要 11 次 DMA 传输。
这是所需的 DMA 传输的数量,假设从每个循环缓冲区中只检索每个效果的一个延迟。在典型应用中,每个数据块的 DMA 传输数量会高得多。例如,混响效果的实现总是需要来自其循环缓冲区的多个延迟。
随着实现的音频效果数量的增加,所需的传统 DMA 传输数量也会增加。因此,系统中可用的传统 DMA 通道的数量会限制可实现的音频效果的数量。
传统 DMA 在音频应用中的局限性
标准 DMA 引擎在以连续或固定间隔移动长数据块时表现良好。固定间隔传输的一个示例是 DMA 引擎访问延迟线的每四个数据样本。
当访问不连续或以固定间隔进行时,典型的 DMA 性能并不是的。当传统的 DMA 引擎移动循环缓冲区数据以生成数字音频效果时,CPU 在处理一个数据块时必须干预至少两次对 DMA 参数进行编程。当数据访问环绕环形缓冲区边界时,CPU 需要对 DMA 参数进行编程,并干预管理延迟线。
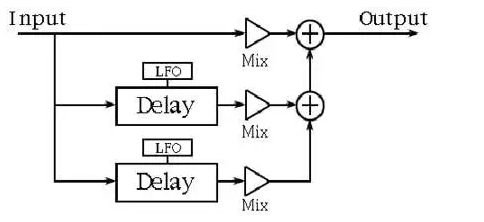
图3. 合唱框图
合唱效果是说明这一点的一个简单算法示例,如上图 3 所示。合唱效果通常用于改变乐器的声音,使其听起来像是多个乐器在演奏,如果乐器中有人声,那么此效果往往会使单个声音听起来像合唱团。我们感知多个声音或乐器,因为当多个声音或乐器同时演奏时,总是存在不的同步和轻微的音高变化。这些是合唱效果的主要特征。
在图 3 中,Chorus 显示为输入与其两个延迟副本的组合。音调偏差是通过延迟输入副本中缓慢变化的延迟量来建模的。延迟缓慢变化,偏差量及其频率由低频
振荡器 (LFO) 控制。
如下图4中的Chorus实现图所示,延迟线是通过使用环形缓冲区(由两个同心圆表示)来实现的。图 4 中呈现的合唱实现意味着使用块处理。此合唱示例中的块大小是四个样本。传入的样本按顺时针方向存储到循环缓冲区中。
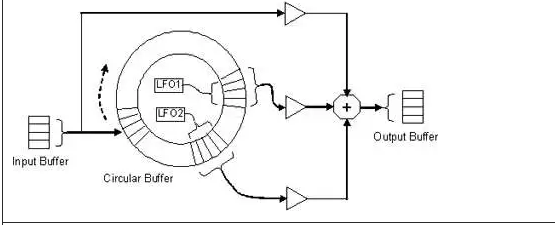
图4. Chorus 实现框图
块处理同时管理数据块(多个样本),而不是只管理一个样本。在此示例中,CPU 等待四个输入样本可用,然后计算四个输出样本。它通过将输入样本块与从循环缓冲区获取的两个延迟数据块相结合来处理这些样本。
在使用传统 DMA 控制器的情况下(如下图 5),每次输入数据块准备就绪时,CPU 都会收到中断通知。然后CPU计算合唱输出。
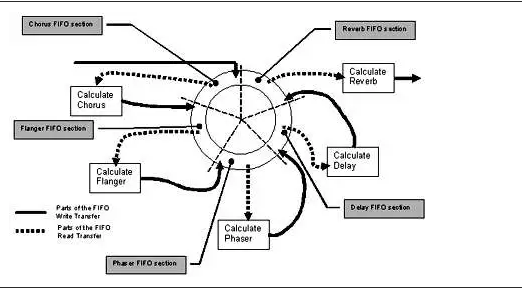
图5. 采用传统 DMA 时 Chorus 实现时间表
本例中的 DMA 引擎分配必须执行两个关键操作:
1) 将一块输入样本存储到循环缓冲区(以供将来参考)2) 从循环缓冲区检索两块延迟数据(为下一个输入样本块准备延迟数据)。
在这种情况下,CPU 必须通过跟踪和编程源地址和目标地址来协助 DMA,并在数据访问绕过缓冲区边界时进行干预。这需要在每次传输之前配置 DMA 引擎。
在 CPU 重新配置 DMA 之前,每个偏移量必须由 CPU 计算(或从预先计算的表中获取)。CPU 带宽得到利用,因为它必须在每次传输之前重新配置 DMA 引擎。在图 5 中,CPU 时间线活动显示为两行:行显示了处理合唱效果所需的 CPU 活动,第二行显示了配置 DMA 所需的 CPU 活动。
在复杂的数字音频效果(例如混响)的情况下,必须从循环缓冲器中检索的延迟块的数量可以达到256或更多。此外,这些延迟块中的每一个都不是固定间隔的,并且随着算法运行,偏移量不断变化。随着循环缓冲区中数据访问量的急剧增加,更复杂的数字音频效果算法(如混响)将需要更多的 CPU 周期。这使得可用于实际应用程序的 CPU 带宽减少。
当多个数字音频效果相继出现时(如图 1 所示),CPU 将必须协助 DMA 移动每个处理阶段所需和产生的数据。在这些任务期间,CPU 和 DMA 必须同步。同步由 DMA 促进,它会中断 CPU。
因此,系统中的中断数量会随着系统复杂度的增加而增加。这些中断会带来很高的开销,因为必须保存寄存器以保留上下文。除此之外,中断还会经过处理管道并破坏指令缓存的微妙效率。保留上下文会消耗大量周期,并进一步改变指令缓存的性能。管道的过度中断也直接影响整体性能。