摘要:为降低粒子群优化算法(PSO:Particle Swarm Optimization)时间和空间的复杂度随问题规模的增大而越来越高的问题,对图形处理器(GPU:Graphic Processing Unit)用于并行计算的方法进行了分析,利用GPU的并行特性,实现了粒子群优化算法路径搜索过程的并行化.测试函数实验结果证明,GPU平台较CPU模式下的计算,其搜索速率有明显提高.
O 引言
图形处理芯片(GPU:Graphic Processing Unit)技术日渐成熟,当前可编程图像处理器已发展为计算技术领域的主力¨‘2 J,在计算技术方面其性能是CPU的数十倍甚至百倍,GPU已经成为现在为强大的计算设备,冲击并超越了CPU独霸的地位,彻底改变当今计算行业的面貌.GPU和其相关软硬件的发展产生了强大的市场动力,因此GPU得到了快速发展.日前GPU的发展速度已经超过了计算机摩尔定律.
并行计算是-f]较为年轻的学科,随着多开发环境的日渐成熟,并行计算的优势得到开发者的重视和认同.笔者将粒子群优化算法的路径搜索过程在GPU平台上实现并行化,利用开发软件的多线程.单指令的GPU架构提高搜索速率,将GPU架构应用于并行计算,取得较好的加速比,从而提高了计算能力.
1 并行计算
并行处理是-f-j综合性的计算机学科,包括硬件技术.算法语言和程序设计等.而并行计算是相对于串行计算而言,同时利用多种计算资源解决计算问题的过程.在时间上,并行是指流水线技术,空间上,并行则是指用多个处理器并发执行计算.在并行计算的过程中,一个任务可能涉及到的问题有:任务分解.任务依赖关系.任务粒度分配.任务交互和并发度等.由于并行计算是用多个处理器去共同完成一个计算任务,能地减少任务完成的实际物理时间,所以相对于串行算法,并行算法能高效解决大规模运算量的问题.笔者研究了如何在更好的平台下进行并行计算,从而加快求解问题的速度,提高求解问题的规模.
2 GPU架构的计算方法
GPU具有强大的计算能力,其架构是专为大量并行运算优化设计的.在绘制图像时,GPU首先接收宿主系统以三角顶点形式发送的几何数据,再由一个可编程的顶点处理器对这些数据进行处理,包括几何变换和亮度计算等三角形计算等;然后,这些三角形由光栅器转换成能显示在屏幕上的单独“碎片”,所有碎片都通过可编程碎片处理器计算终颜色值.GPU在处理大尺寸图像时具有的优势,如在8 192×8 192像素图像的直方图生成中,排除内存分配.读回的时间和数据加载后,GPU的时间消耗仅为19 ms左右,计算效率是CPU的17倍之多.基于GPU的信息抽取算法,能使图像的文本语义信息描述更加细致完整,系统的功能和性能获得很大提升.
GPU计算一般采用Brook编译,Brook支持所有带附加流数据的c句法,流数据存储于GPU的存储器中,而核函数也在GPU上执行.早期Brook编译效率很低,只能使用像素着色器进行运算.同时Brook也缺乏有效的数据通信机制.AMD(Advanced Micro Devices)公司采用Brook的改进版本Brook+作为开发语言,提高了效率.由于GPU具有高效的并行性和灵活的可编程性等特点,越来越多的研究人员和商业组织开始利用GPU完成一些非图形绘制方面的计算,并开创了新的研究领域.GPU在高性能计算方面所具有的优势体现在:高效的并行性.超长的图形流水线.高密集的运算.控制简单和分多个阶段执行等方面.早的GPU开发直接使用图形学的应用程序编程接口(API:Application ProgrammingInterface)编程.这种开发方式首先要求将数据打包成纹理,然后将计算任务映射为对纹理的渲染过程,用汇编或者着色语言编写shader程序,然后通过图形学AP(Application Processor)执行.
NVIDIA公司推出了统一的计算设备架构(CUDA:Compute Unified Device Architecture),所以,当前GPU“摒弃”传统的图形应用处理器AP.这种框架使用并行计算内核函数,使GPU能解决复杂的计算问题.一个完整的CUDA程序是由一系列的设备端kernel函数的并行步骤和主机端的串行处理步骤共同组成的,每个kernel内核函数在一个由多个大小相同.组织为一维或二维的线程块网格中被执行,线程的总数等于每个块中的线程数与块数的乘积.同一线程块内的线程可通过高带宽的共享存储器进行协作,软件开发人员可以基于CUDA平台开发计算软件,用户可以用比以往少得多的时间完成多个计算任务.
其显着的优点是提高计算的速率.现有多种软件工具和语言可以简化GPU的编程工作,同时产生GPU开发的计算工具包,能利用GPU平台进行排序及线性方程组的求解,实现并行的搜索算法.离散优化算法等多种科学计算.
3 GPU架构下的并行算法
粒子群优化算法(PSO:Particle Swarm Optimization)是处理连续优化问题的算法.
PSO算法的计算公式如下:
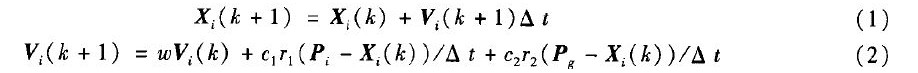
但该算法仍存在下述问题:随着问题规模的增大,计算时间和空间的复杂度越来越高.为减小计算的复杂度可让多只蚂蚁在GPU的核处理器上进行并行搜索,即将路径搜索的过程在GPU上实现并行化,在基于CUDA平台开发软件的多线程.单指令的架构上提高搜索速率.从而降低算法在时间和空间上的复杂度.笔者采用如图1所示的流程对不同粒子数的运行时间进行实验,利用Windows XP操作系统,Pentium 2.66 GHz CPU环境,对实验测试函数:

进行实验运算,其中d表示搜索范围(一100-100).采用不同的处理器进行运算时,若速度提高S倍,则称该任务的加速比为S,定义为:
其中咒表示用GPU处理器所需要的物理时间,k表示用CPU处理器所需要的物理时间.实验结果如表1所示.
由表l可看出,PSO算法在GPU与CPU不同平台的加速比与粒子数有关,当粒子数大于820时,GPU架构算法的速度开始大于CPU算法速度,并随着粒子数的增大,其加速比也明显增大.实验结果证明,当粒子数为某个固定数值时,基于GPU架构的高浮点数计算的并行特性,GPU模式相比CPU模式下的计算,可提高算法的速度,降低算法的复杂度.
4 结语
笔者利用GPU提供的平台进行并行计算,通过提高速度缩短计算任务的完成时间,这是利用并行处理器的强大能力实现的创新.随着GPU芯片集成技术的优化改进.目前在信息检索.生物基因技术领域.人工神经网络并行分布性处理.数据挖掘等方面,GPU已经突破了很多技术屏障.GPU这种为强大的计算设备,正在改变计算行业面貌,如在图片和视频的处理,分类.解析几何等方面的应用.支持CUDA的GPU可以成为由若干个向量处理器组成的超级计算机.GPU的架构还会不断优化,CPU和GPU各有所长.CPU的资源多用于缓存,GPU的资源多用于数据计算.如果将二者组合,相互取长补短,将融合得情况来提高电脑的运行效率,提高性价比,为人们带来新的选择.CPU在GPU的影响下也逐渐找回自己的优势.未来算法执行的架构会越来越倾向CPU/GPU集群的协作模式.整合后的模式较传统的CPU将有更为突出的优势.
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。