摘要: 描述了一种基于免疫学理论的入侵检测系统的体系结构,简要说明了系统的特点,介绍了免疫检测器的生成模型和生命周期。
计算机安全的多数问题都可以归结为对自我(合法用户、授权的行动等)和非我(入侵者、计算机病毒等)的识别,而生物免疫系统千百万年来一直在努力解决这一问题。Stephanie Forrest等人从生物免疫系统中受到启发,提出了基于免疫系统基本原理的异常检测。
1 免疫系统原理
生物免疫系统的保护机制分为非特异性的和特异性的两种。非特异性免疫力,又称自然免疫力,针对任何病菌提供一般性的保护。例如,人体皮肤对人体的保护作用,针对细胞损伤的发炎反应等。特异性免疫力,又称获得性免疫力,针对某种特定的病菌提供保护。例如,某种抗体对病菌的反应。同样,计算机安全机制也可以分为非特异性的(例如,安全编程规则,防火墙,加密等)和特异性的(例如,病毒特征检测,脆弱性分析工具等)。然而,多数非特异性保护机制都是消极的,它们只是阻止入侵者进入系统而对成功进入系统的入侵者或发自内部的恶意行为无能为力;而特异性保护机制通常滞后于层出不穷的新的攻击方法。所以,应该将非特异性保护机制与特异性保护机制结合起来,如生物免疫系统一样,为计算机系统提供综合的、多层次的保护。
生物免疫系统中淋巴细胞在胸腺中产生。T淋巴细胞,简称T细胞,是免疫系统中多种特异性细胞之一。淋巴细胞的表面覆盖着受体,受体能与抗原绑定。每个淋巴细胞具有一种特异性受体,每一种受体与一小群结构相近的抗原绑定。T细胞上的受体由一伪随机过程产生。当T细胞在胸腺中成熟时,他们要经历一个称作“阴性选择”的检查过程。在这一检查过程所谓阴性选择,就是将新生而未成熟的免疫细胞与生物体自身细胞进行匹配,如果成功,则将此细胞杀死,只有那些与所有自身细胞都不匹配的细胞,终才得以脱离胸腺,成为成熟的免疫细胞。之所以要这样,是为了避免发生免疫细胞杀死自身细胞的自免疫反应。匹配过程中所使用的是r-邻近位算法:即如果2个基因链有至少r个邻近位相同,就称它们匹配,其中r是匹配规则的一个参数。为简单起见,用二进制串(0或1)来表示基因链。例如对于r=5,称2个基因链1000111101011010和0101011101101000是匹配的,而1010010001000110和0101001011100010是不匹配的。
2 基于免疫理论的网络入侵检测系统设计
下面主要考虑以下3个问题:网络数据包特征以及免疫检测器生成过程和整个系统的体系结构。
2.1 网络数据包特征
网络IP包由很多域(fields)组成,这些域标明了路由、包的功能以及状态标志等信息。数据包头各域及取值如表1所示,表中分别列出了数据包的IP域、TCP域、UDP域和ICMP域的27种特征以及这些特征的可能取值。其中还有部分域没有列出。需要强调的是,尽管数据包的有效载荷(payload)部分也包含许多对入侵检测有用的信息,但如果把它们考虑在内,将使程序搜索空间骤然增大,进而导致搜索效率急剧下降。因此,这里仅对数据包头进行分析。
从表1可以看出,需要进行匹配的位串长度高达217位,所以很有必要根据随机原则选择部分域进行匹配,以提高匹配速度和系统的处理效率。
2.2 免疫检测器的生成模型及生命周期
免疫检测器是整个入侵检测系统的,其生成模型如图1所示。其中基因库中存放的就是随机生成的针对网络数据包头的免疫检测器。这里所谓的随机,主要包含3个方面的含义:(1)随机选择包头的27个特征的其中一部分。(2)随机选择协议。(3)随机定义各个特征的取值范围。这样就可以显著缩短匹配二进制串的长度。
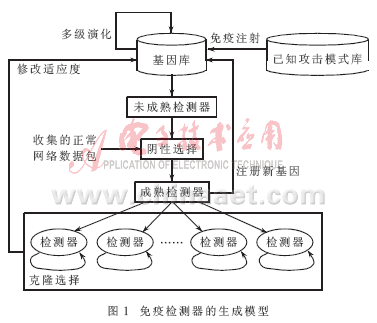
从基因库取出部分随机产生的免疫检测器,组成未成熟的检测器集R0,然后使用大量收集来的正常网络数据包作为自我集,利用以上的r-邻近位不完全匹配算法在R0上作阴性选择。通过了阴性选择的检测器则成为成熟的检测器集R。把R注册(复制)到初始基因库中,同时,把它们分布到网络中的重要节点上,就可以进行入侵检测了。
需要注意的是,人体随机生成的免疫细胞有98%被阴性选择所淘汰,仅有2%的免疫细胞能通过阴性选择而存活下来。免疫检测器的生成如同生物体一样,实际是一个时间复杂度非常大的循环往复过程。该过程对于人体这种高度并行的分布式系统来说是可以忍受的,但对于入侵检测系统来说却无法容忍。可以通过对基因库进行多级演化,使其生成合格免疫检测器的几率大大增加,从而使检测器生成过程的时间复杂度降低。
此外,还可使用已知攻击模式库对基因库进行免疫注射。该过程相当于人类打预防针,使之能够识别并抵抗已知攻击。这样做也是为了加快免疫检测器的产生过程并提高产生效率。
不难看出,免疫检测器生成过程的实质就是找出自我空间S,然后用检测器尽可能覆盖非我空间不论已知攻击还是未知的新攻击,也不管攻击过程如何,它们产生的结果都隶属于非我空间。所以,只要免疫检测器能够尽可能地覆盖到非我空间,则它一定可以检测到未知攻击。
需要强调的是:成熟的免疫检测器并非永远在系统中存在,而是具有一定的生命周期。这样做有2方面原因:(1)为了保证系统的平衡,使得免疫识别器不会无限制增长。(2)使适应度低的检测器死亡,适应度高的检测器进行克隆选择,从而能够更快地对已知入侵进行响应。每个检测器都具有一定的适应度(设为匹配阈值t的倒数,即1/t)和生命期。如果检测器在规定生命期内匹配不成功或未达到匹配阈值t,则它会自动死亡。此时系统会自动生成一些新的检测器,使系统重新达到平衡;而如果检测器在规定时间内达到匹配阈值t,则它就会被激活,对已有入侵进行反应,并且通过克隆选择过程成为记忆型检测器。系统会延长此类检测器的生命期,并提高它们的适应度,即降低它们的激活阈值t,使得它们更容易存活和被激活,从而使得相似攻击再次到来时,系统能够快速作出反应。
2.3 体系结构
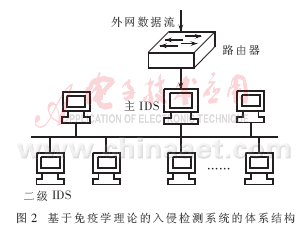
免疫IDS可分为2层:主IDS和二级IDS。这类似于人体免疫系统中的淋巴节点和二级淋巴节点。基于免疫学理论的入侵检测系统的体系结构如图2所示。其中主IDS部署在路由器之后,它接收所有来自外网的数据,并根据它们生成免疫检测器,并将成熟的免疫检测器分发到各个主机节点中,使之成为二级IDS。它主要负责检测本机网络中是否有非我数据包存在,并且根据实际情况,进行克隆选择过程。免疫检测器依然是使用r-邻近位匹配规则与数据包进行匹配。
3 系统的特点
由于借鉴了生物免疫系统的一些思想,该入侵检测系统能够有效地检测未知新攻击。此外,它还具有以下特点。
(1)轻量级:由于该系统仅对网络数据包头进行分析,因此处理速度较快,对整个网络速度的影响不是很大。
(2)分布性:成熟的免疫检测器分布到整个LAN的各个关键主机上,它们分布并行地工作,能够在较小的局部范围内发现并处理入侵。而且整个入侵检测系统具有比较简单的层次结构,能够有效地避免单点故障问题。
(3)自适应性:系统具有较好的自适应能力,能够根据实际情况不断修改检测器的适应度和生命期,使之能更有效地对付入侵。
4 小 结
本文仅提出了一个入侵检测的框架模型,下一步的工作就是在该模型的基础上构筑系统。此外,如何使用尽可能少的免疫检测器来覆盖尽可能大的非我空间等效率优化问题也是将来需要进一步研究的内容。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。