1 引言
H.264基本概况
随着HDTV的兴起,H.264这个规范频频出现在我们眼前,HD-DVD和蓝光均计划采用这一标准进行节目制作。而且自2005年下半年以来,无论是NVIDIA还是ATI都把支持H.264硬件解码加速作为自己值得夸耀的视频技术。H.264到底是何方“神圣”呢?
H.264是一种高性能的视频编解码技术。目前国际上制定视频编解码技术的组织有两个,一个是“国际电联(ITU-T)”,它制定的标准有H.261、H.263、H.263+等,另一个是“国际标准化组织(ISO)”它制定的标准有MPEG-1、MPEG-2、MPEG-4等。而H.264则是由两个组织联合组建的联合视频组(JVT)共同制定的新数字视频编码标准,所以它既是ITU-T的H.264,又是ISO/IEC的MPEG-4视频编码(Advanced Video Coding,AVC),而且它将成为MPEG-4标准的第10部分。因此,不论是MPEG-4 AVC、MPEG-4 Part 10,还是ISO/IEC 14496-10,都是指H.264。
H.264的优势是具有很高的数据压缩比率,在同等图像质量的条件下,H.264的压缩比是MPEG-2的2倍以上,是MPEG-4的1.5~2倍。举个例子,原始文件的大小如果为88GB,采用MPEG-2压缩标准压缩后变成3.5GB,压缩比为25∶1,而采用H.264压缩标准压缩后变为879MB,从88GB到879MB,H.264的压缩比达到惊人的102∶1!H.264为什么有那么高的压缩比?低码率(Low Bit Rate)起了重要的作用,和MPEG-2和MPEG-4 ASP等压缩技术相比,H.264压缩技术将大大节省用户的时间和数据流量收费。尤其值得一提的是,H.264在具有高压缩比的同时还拥有高质量流畅的图像,正因为如此,经过H.264压缩的视频数据,在网络传输过程中所需要的带宽更少,也更加经济。
2 H.264解码器原理
H.264编码器结构系统由以下几部分组成:网络数据提取层(NAL)、VAL缓存器、熵解码、反扫描反量化反变换、帧间预测、帧内预测、图像参考帧缓存器、去方块滤波,如图1所示。首先从码流中获取NAL单元数据,通过RBSP解析出序列参数集、图像参数集和图像数据。把数据和参数存储在VCL缓存器中,然后再在视频编码层(VCL Table)中熵解码。熵解码模块(VLD)解析所有参数和参考图像索引等,提供各种控制信息和残差数据。通过反量化反变化先将一维数据转换成二维数组或矩阵,再通过逆扫描过程将变换系数量化值序列映射到对应坐标,主要有逆zig_zag扫描和逆场扫描两种模式。之后读取数据读取并进行判断、帧内预测和帧间预测,再综合所有预测和反变换反量化的数据,进行方块滤波,这样能够大大减轻因预测、量化而产生的块效应,从而获得更好的主观图像质量和客观性能。同时还可选取已恢复的图像作为后续处理图像的参考帧。
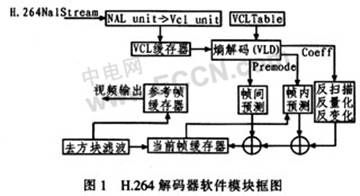
3 DSP-BF533的解码器设计与优化
3.1 解码器软件设计框图
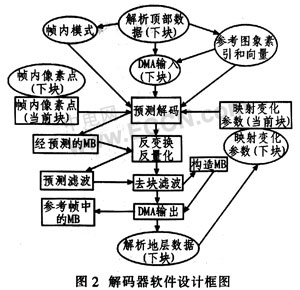
根据DSP-BF533的内含存储器控制器(DMA)的特点,设计一个整合DMA的解码流程,如图2所示。把两个与DMA有关的步骤添加到普通解码器中,步骤1是从片外存储器中读取数据;步骤2是将已处理好的数据输出到片外存储器。
从图2中可看到具体流程:①对下一个宏块进行顶部数据分割,分割出残差数据之前的数据。同时为解码提供帧内预测、参考图像索引和向量;②启动DMA读取分割出来的数据,其中也要读入解码参考图像索引和向量;③对图像数据进行帧内预测;④利用底部分割读入的映射数据,进行反变换和反量化;⑤通过滤波重建图像;⑥通过DMA把图像数据输出到片外和片内存储器;⑦对下一个宏块进行底部数据分割,然后取出映射数据供下一个宏块解码使用嘲。
为了避免DSP内核等待DMA读人数据,把解码数据预先从宏块中分割成顶部数据和底部数据,顶部数据包括残差数据之前的数据,剩下的数据就是底部数据。如果有P帧到来时数据已事先分割,然后DMA启动。当DSP内核在解码当前宏块时,DMA读入下一个宏块。如果在当前宏块参考数据需要利用时,此数据解码完成后还可通过DMA输入到片内存储器。因为当前宏块顶部数据对下一个宏块的滤波没有参考价值,所以这些宏块顶部数据就被DMA传送到外部存储器。该设计第1个宏块未进入解码过程,因为初始状态时一系列参考图像和参数都没有设定,所以第1个宏块只是设定解码器参考图像和参数行初始化,为下一宏块解码使用。宏块数据的分割和DMA的数据读入都可在解码中并行执行,即执行当前宏块时可设定下一个宏块所需参数以及读入解码数据,这样可减少各模块间的等待时间,提高工作效率。上述可并行执行的过程如图2中以椭圆方框表示。
3.2 软件流水新型算法
很多设计中,解码参数准备、解码和DMA的数据输出等过程按顺序串行执行的,该设计有条理安排这3个过程并行执行,充分利用DSP-BF533的指令并行执行特点,减少各软件模块之间的等待时间。
下面以4×4的宏块矩阵为例,首先给4×4矩阵标上4行4列的坐标,然后把程序处理分成5个阶段.其状态分别按顺序对应1、2、4、8、16,以便状态机运算,如表1所列。CAVLC为解析读入的数据并为后续的图像整合重建提供参数和参考图像等数据的过程,hl_decode是解码过程,即根据准备好的条件综合重建图像的过程。DMA是对已解码数据的传送过程。对照表1和表2分析:当新的一帧图像到来时,当前状态标号为1,此时只有CAVLC执行;当运行到坐标为x=1,y=0时,进入第2个状态,当前状态标号为2,CAVLC和hl_decode并行执行;当运行到坐标x=1,y=1时,进入第3个状态,标号为4,3个模块同时并行执行;到坐标y>4时,进入第4个状态,标号为8,只有hl_decode和DMA两个并行执行,CAVLC已经完成对所有宏块的解码前准备工作;再判断x>0,进入第5个状态。标号为16,此时只运行DMA模块。
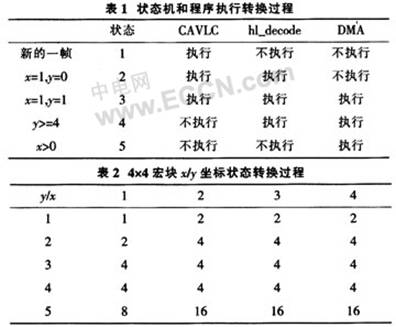
因此,解码第1个宏块时处在状态1,之后连续4个宏块是状态2,再连续11个宏块进入状态3,随后1个宏块是状态4,3个宏块进入状态5。
如果假设CAVLC的执行时间A,hl_decode的执行时间B,DMA的执行时间C,普通算法的执行总时间T=16A+16B+16C;本文提出的方法时间T2=A+16B+3C,因此,明显缩短了程序执行时间。
4 测试结果
在DSP-BF533测试平台上测试Claire.cif和Pairs.cif,可以得出:优化后的结果提高解码速率,达到实时应用要求。结果如表3所列。

5 结束语
基于DSP的新型的软件流水算法,可以获得更高更可靠的解码效率,DSP再让我们见识到了它的神奇。
[1]. H.261 datasheet https://www.dzsc.com/datasheet/H.261_2060787.html.
[2]. AVC datasheet https://www.dzsc.com/datasheet/AVC_1518400.html.
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。