根据处理器芯片的指令及其实现形式,我们可以把处理器芯片分为复杂指令系统(CISC)和精简指令系统(RISC),前者追求单条指令的强大功能以简化编程;后者强调指令的简化以提高硬件效率。由于RISC具有指令长度一致、单周期执行时间、易于并行和流水线处理等优点,绝大多数的DSP处理芯片都采用了RISC.另外,根据计算机的存储器结构及其总线连接形式,计算机系统可以被分为冯诺依曼结构和哈佛结构,前者共用数据存储空间和程序存储空间,共用存储器总线;后者具有分离的数据和程序空间及分离的访问总线。由于哈佛结构在指令执行时,取指和取数可以并行,因此具有更高的执行效率,所以大多数的DSP芯片都采用了哈佛结构。
数字信号处理(Digital Signal Processing,简称DSP)是一门涉及许多学科而又广泛应用于许多领域的新兴学科。20世纪60年代以来,随着计算机和信息技术的飞速发展,数字信号处理技术应运而生并得到迅速的发展。数字信号处理是一种通过使用数学技巧执行转换或提取信息,来处理现实信号的方法,这些信号由数字序列表示。在过去的二十多年时间里,数字信号处理已经在通信等领域得到极为广泛的应用。德州仪器、Freescale等半导体厂商在这一领域拥有很强的实力。其工作原理是接收模拟信号,转换为0或1的数字信号。再对数字信号进行修改、删除、强化,并在其他系统芯片中把数字数据解译回模拟数据或实际环境格式。它不仅具有可编程性,而且其实时运行速度可达每秒数以千万条复杂指令程序,远远超过通用微处理器,是数字化电子世界中日益重要的电脑芯片。它的强大数据处理能力和高运行速度,是值得称道的两大特色。
ADSP2106x就是一款采用超级哈佛结构和RISC的DSP处理芯片,其强大的浮点、定点运算功能和大容量的片内存储器,使其可以胜任苛刻的实时信号处理任务;而它丰富的外部接口和10个通道的DMA可以使所处理数据的畅通无阻[1];再加上片内的仲裁逻辑,6个ADSP2106x和一个主机可以很容易连在一起构成一个并行处理系统。利用ADSP2106x可以开发出功能很强的信号处理系统[2].
虽然ADSP2106x芯片本身提供了优异的性能,但该性能的发挥离不开软件编程的支持。比如,ADSP2106x的峰值运算速度可达120MFLOPS(主频40MHz),即在一个时钟周期内可以完成乘法、加法和减法,但这三个并行运算指令是需要合理安排才能实现的。另外,由于芯片内部采用了超级哈佛结构,因此可以在一定条件下同时存取两个数据,但这也需要合理安排数据在数据存储器和程序存储器中的放置,才能使并行的存取指令有效。
本文主要介绍ADSP2106x中并行指令的一些应用技巧,重点针对并行运算指令和数据存取指令。通过这些技巧的应用,可以提高编程效率,充分发挥硬件潜力,同时对ADSP2106x的内部结构有更为深入的了解。
ADSP2106x中的运算处理单元
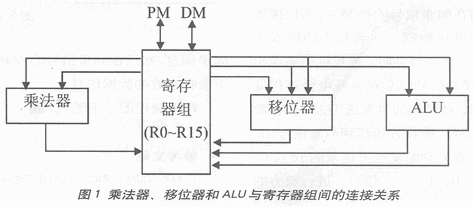
ADSP2106x中的处理部分包含了三个运算单元:ALU、乘法器和移位器,它们与寄存器组间的连接关系如图1所示[3].三个运算单元的功能如下:
(1)ALU单元:定点、浮点加减法和求平均;逻辑运算;求、值、值、限幅、比较;定点<-->浮点转换。
(2)乘法器:浮点乘法;定点乘法及乘法累加。
(3)移位器:移位操作;位操作;位场(bit field)提取和存储。
ADSP2106X是AD公司的一种高性能32位浮点DSP,它的基本特点有:
·工作频率为40MHz,时钟周期25ns.
·数据线有48根,地址线有32根,地址范围4G.
·所有指令都是单周期指令,指令长度均为48bit.
·32-bit IEEE浮点运算单元,内含乘法器、ALU和移位器,支持40bit的扩展浮点运算。
·10个DMA通道。
·4M bit双口片内存器。
·有两个同步串口和六个连接口。
·支持多处理器共享总线。
寄存器可以在一个时钟周期内从数据存储器和程序存储器中各存取1个数据,这正是ADSP2106x超级哈佛结构的优势。另外,运算单元的运算与寄存器的存取可以并行不悖,但在编程时,这种并行往往伴随一个流水线的过程。
ADSP2106x中的乘法器和ALU还具有并行运算的能力;在一个时钟周期内,乘法器可以完成乘法,ALU可以同时完成加法和减法,这使ADSP2106x在40MHz的主频下达到了120MFLOPS峰值运算速度。
下面针对这种并行运算来考虑软件编程时应注意的问题。
并行运算指令的基本格式
ADSP2106X提供了强大的实现多处理器并行处理的能力,允许某一处理器直接访问其它处理器的内部双口SRAM,并且这种访问一般不影响被访问处理器的工作,片内的分布总线仲裁逻辑可直接管理6片ADSP2106X和一个宿主机组成的并行系统的信息交换。另外ADSP2106X还具有6个4bit的连接口(Link Ports),每个连接口可以两倍于系统工作时钟的速率传送数据,因此每个连接口在一个时钟周期内能够传送一个8bit数据。在多处理器应用中,ADSP2106X通过其它6个连接口实现处理器之间点到点的通信。由ADSP2106X构成的典型多处理器并行系统主要有以下三种形式:共享总线的多处理器并行系统;MeshSP(网络)结构多处理器并行系统;集束多处理器并行系统。
ADSP2106x中并行运算指令的基本格式如下图2,这里我们以浮点运算为例,如果是定点运算,只需把所有的前缀"F"换为"R"即可。

并行指令中各操作的顺序必须符合图中的要求,并以逗号隔开,否则编译时会出错。
DM地址产生寄存器的范围为0~7, PM地址产生寄存器的范围为8~15;即
I0≤ Ia ≤ I7, M0≤ Mb ≤ M7; I8≤ Ic≤ I15, M8≤ Md ≤ M15.并且很重要的是:DM(Ia,Mb)实际指向的内存地址范围必须在数据存储器中,对于ADSP21060,在32位数据长度下,其数据存储器的地址范围为0x30000~0x3FFFF; PM(Ic,Md)实际指向的内存地址范围也必须在数据存储器中。否则虽然编译时能通过,但运行时达不到并行的效果,而且很可能出错,此种出错具有一定的不确定性,在程序调试时不易发现,潜在的危害很大。
在乘法器和ALU并行时,对它们从寄存器中获得操作数有严格的要求。16个寄存器被分成4组,F0~F3为组,F4~F7为第二组,F8~F11为第三组,F12~F15为第四组。当乘法器和ALU运算并行时,乘法器的两个操作数必须分别取自于组和第二组;ALU的两个操作数必须分别取自于第三组和第四组。
在上面并行处理中,任一寄存器都可以既被读又被写;在指令执行时遵循先读后写的原则,即在前半个时钟周期里数据从某个寄存器中被读出,在后半个时钟周期里运算结果又被回写到该寄存器中。对这一点的深刻理解有助于在编程时采用流水线的步骤。
并行处理时的流水线步骤
在采用ADSP2106x并行指令编程时,由于数据在内存到运算单元之间的流通必须以寄存器为中介,因此编程时需要采用流水线的步骤。我们以下面例子为通用格式来表示该流水线步骤。
假设内存中有N个数据:xn, 0≤n≤N-1;对其经过某种运算处理后,得到N个处理结果:yn,0≤n≤N-1,并把yn写回内存。如果我们不采用并行处理,则处理步骤如下:
For n=0 to N-1
Fx ← 内存(xn);
Fy = 运算(Fx);
Fy → 内存(yn);
End
上述处理共需要3*N个时钟周期(不考虑循环的初始化)。如果我们采用下面的并行处理,且把数据从内存?寄存器?运算单元?寄存器?内存的流通步骤进行下面的流水线化,
Fx ← 内存(x0);
Fy = 运算(Fx), Fx ← 内存(x1); /*进入循环的准备操作 */
For n=2 to N-1
Fy = 运算(Fx), Fx ← 内存(xn), Fy → 内存(yn); /*并行处理循环体 */
End
Fy = 运算(Fx), Fy → 内存(yN-2);
Fy ? 内存(yN-1); /*退出循环后的回写操作 */
则总处理时间缩短为N+2个时钟周期。此时,为了使循环体中并行指令能够实现,需要在进入循环体之前完成数据预取的准备操作,在循环体退出后完成运算结果的回写操作;同时要求xn和yn分处于程序存储器和数据存储器中。
两个实例
实例1为求两个数组内积。设xn, yn, 0≤n≤N-1为两个数组,它们的内积定义为:
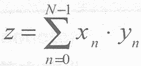
为了在运算中能够同时获得xn和yn,我们需要把xn和yn分别安排在程序存储器和数据存储器中,经过运算后,内积结果在寄存器f8中。
f8=0; /*对结果寄存器清零 */
i0=x; m0=1; /*把数组xn的首地址赋给i0 */
i8=y; m8=1; /*把数组yn的首地址赋给i8 */
f0=dm(i0,m0), f4=pm(i8,m8);
f12=f0*f4, f0=dm(i0,m0), f4=pm(i8,m8); /*为进入循环作准备*/
lcntr=N-1, do loop until lce;
loop: f12=f0*f4, f8=f8+f12, f0=dm(i0,m0), f4=pm(i8,m8); /*并行处理循环体*/
f12=f0*f4, f8=f8+f12;
f8=f8+f12; /*退出循环的残余操作,内积结果在f8中 */
第二个例子是复数乘法运算,复数乘法需要4次实数乘法、实数加法和实数减法,因此至少需要四条指令才能完成复乘法,在这四条指令中,还要完成四个操作数的读入和两个结果的回写。这里,我们假设有两个复数组:xn=xrn+j*xin与yn=yrn+j*yin,0(n(N-1;二者相乘后得到zn=zrn+j*zin=(xrn*yrn-xin*yin)+j*(xrn*yin+xin*yrn),0(n(N-1.xr、yr及zi被安排在数据存储器中,xi、yi及zr被安排在程序存储器中。具体程序如下,
i0=xr; i1=yr; i3=zi; i8=xi; i9=yi; i10=zr; m0=1; m8=1; /*对地址产生寄存器赋初值 */
f0=dm(i0,m0), f4=pm(i9,m8); /* f0= xr0, f4= yi0*/
f5=dm(i1,m0), f1=pm(i8,m8); /* f5=yr0, f1=xi0 */
f8=f0*f5; /* f8= xr0* yr0 */
f12=f1*f4; /* f12= xi0* yi0 */
f9=f0*f4, f2=f8-f12, f0=dm(i0,m0), f4=pm(i9,m8); /* f9= xr0* yi0, zr0=f2= xr0* yr0- xi0* yi0 */
/* f0= xr1, f4= yi1*/
f13=f1*f5, f5=dm(i1,m0), f1=pm(i8,m8); /* f13= xi0* yr0 , f5=yr1, f1=xi1 */
lcntr=N-2, do CMTI until lce;
f8=f0*f5, f3=f9+f13; /* f8= xr* yr , zi=f3=xr* yi+ xi* yr */
f12=f1*f4, dm(i3,m0)=f3, pm(i10,m8)=f2; /* f12= xi* yi, 存zi与zr */
f9=f0*f4, f2=f8-f12, f0=dm(i0,m0), f4=pm(i9,m8); /* f9= xr* yi, zr=f2= xr* yr- xi* yi */
/* f0= xr, f4= yi */
CMTI: f13=f1*f5, f5=dm(i1,m0), f1=pm(i8,m8); /* f13= xi* yr , f5=yr, f1=xi */
f8=f0*f5, f3=f9+f13;
f12=f1*f4, dm(i3,m0)=f3, pm(i10,m8)=f2;
f9=f0*f4, f2=f8-f12;
f13=f1*f5;
f3=f9+f13;
dm(i3,m0)=f3, pm(i10,m8)=f2;
结语
本文对ADSP2106x芯片内部运算处理单元的结构进行了分析,并在此基础上总结了并行处理指令的一般格式和具体应用中的流水线步骤,给出数组内积和复数组相乘的两个典型例子。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。