自适应计算机( ACM,Adaptive Computing Machine)是一类新颖的数字式IC,可以作为未来移动装置和无线电手机的计算平台。QuickSilver Technology公司(位于加州的San Jose),是一家移动通信系统公司。该公司正在推出一种用'硅CMOS器件的新颖的结构。这种结构可以提高器件的性能,减少其功率消耗,并缩小其芯片面积。这种结构方法被命名为'自适应计算机',是一种新类型的数字式集成电路,可以作为计算平台,广泛应用于未来的移动装置,和无线电手机。
QCELP,即QualComm Code Excited Linear Predictive(QualComm受激线性预测编码),它的8个内编码环路,消耗了QCELP算法中绝大部分的功率。一个QCELP算法,如果运行在DSP芯核上,大约消耗84 mW.此项数据取自一个0.25μm CMOS的SOC芯片的试验结果,此SOC嵌入有DSP功能块与存储器,芯片面积约为4mm2.
编码器的任务是确定描述话音音频段的小的参量组,话音音频段可以的位数表示。编码器发送参量到译码器,译码器用这些参量重建音频段。一旦重建完成,音频段便在扬声器系统播放。话音产生系统可模拟为声束、声调、周期激励器(声卡)或剩余噪声源。声束用线性预示编码模拟。声调和剩余噪声激励声束并用码簿(codebook)编码。
用码簿索引选择来自码簿的高斯向量(见图1)。向量也称之为激励信号,向量与增益值相乘并经2个线性滤波器滤波。第1个滤波器之为长项滤波器,它重建激励信号中语音的长项声调周期数。第2个滤波器(短项滤波器)模拟话音的谱形。短项滤波器的输出是合成语音。
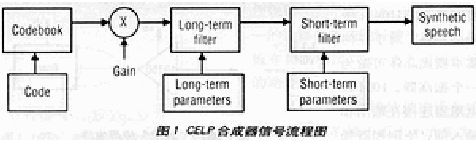
LPC(线性预示编码)滤波器的频谱是语音信号的谱线包络。所以,滤波器产生话音幅度。合成器产生向量或话音取样N长度的子帧(在8KHz取样率时,N为10~40)。合成器参量以帧或子帧速率更新,一般1帧是4个子帧长。
通常,码簿索引(码)、码簿增益和长项预示参量以子帧速率更新。对于IS-96A WCELP-13,码簿参量以到16倍帧或4倍子帧速率更新,短项滤波器系数以帧速率传送到合成器,但通常以子帧速率线性内插。
合成分析
CELP编解采用人声音产生系统的模型,它由声束、声卡、送话器嘴和语音组成。此系统可用一个噪声源、一个音调合成滤波器和声束或共振峰合成滤波器进行模拟。话音合成器或解压缩单元的数据流激励音调滤波器(图2)。然后,信号由共振峰合成器或LPC滤波器处理,是后滤波。
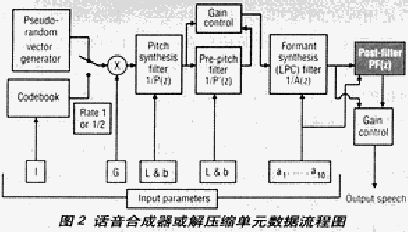
合成器和分析器把话音分解为段(帧)。在8KHz取样率时(160个取样),帧长度是20ms话音长。对于每帧,分析器确定在多大数据率下可地表示帧。速率为全,半,1/4和1/8四种。噪声源依刺于帧速率。1/4和1/8速率用于伪随机噪声源,全和半速率用于码簿。
分析器的工作是为当前话音帧确定全成器模型参量的匹配。分析器或压缩单元用合成器的简化型式搜寻一帧话音的参量。在数据流框图(图2)中表示为逆向工作过程。
用合成分析方法(有时称之为向量量化器)求得音调和码簿参量(见图3)。此过程包括为音调确定或搜索算法选择延迟参量和为码簿搜索选择索引。思想是测量与相关函数匹配的特性,相关函数与目标话音段比较时再现合成信号的误差。根据延迟或索引产生的误差信号选择是佳延迟或码簿索引。
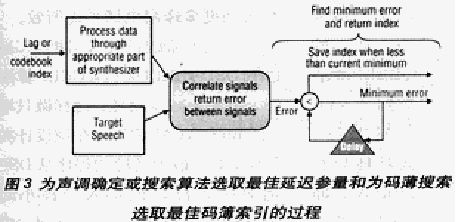
对每个延迟和码簿索引,都必须执行通过合成器的数据处理和信号关联。用可编程DSP实现这两种搜索会占用大部分的计算时间和功耗。QCELP算法也需要用32位运算做绝大部分相关测量。
功率消耗程序
有8个主要的内部码环路或程序消耗绝大部分的QCELP功率。它们是码簿和声调搜索,线频谱对(LSP)计算,递归卷积和4个不同的滤波器。在QCELP的分析器/压缩器侧用DSP实现,3个内部码环路占总功耗的80%.其中声调和码簿搜索占49%;LSP和余弦占16%;各种滤波器占其余14%.在合成器/解压缩器侧,各种滤波器占功耗的56%左右,而其他功能(如正弦,余弦和除法)占别外5%.这两种QCELP函数总计占功耗的61%.
随着QCELP算法日益普及和应用(如蜂窝电话所需功能的增加),传统的DSP/微处理器和ASIC方法开始失去它们的优执。但自适应计算机(ACM)技术对各种便携设计(包括蜂窝电话)是一种更有效且功耗更低的大有前途的方法。
更多性能
随着要求低功耗而同时保持高性能的发展趋势。便携系统设计人员花精力分析当今技术是值得的。这样做的一种方法是比较计算效率(CPE-computational power efficiency),CPE是比较当今设计技术优缺点的量度。CPE定义为在一个时钟周期内能解决问题的有效工作门数与器件总门数之比。
一个典型的DSP芯片或嵌入式芯核的CPE是10%左右(见图4)。这意味着在一个DSP芯核或芯片中一般只有10%的门在任一时间内执行真正的工作,表明处理器只有一小部分正在真正在执行有用的工作,其余部分是额外消耗,用以维持处理器中有效工作的那一部分。

ASIC的平均CPE是25%左右,是DSP方案的2.5倍,这些增益可提高性能或降低功耗,是以牺牲灵活性来实现。ASIC设计周期中的任何不可预见的变化都会导致整个ASIC的重新设计。
ACM的CPE是60%,比ASIC好2.5倍。ACM器件也具有算法可编程的优点,这种技术允许一种算法以短的时间运行在有效的硬件中。这使得便携无线系统在支行时间能随时适应任务。这意味着不需要改变算法来适应预先确定的处理器硬件。一个算法所需的硬件产生算法运行所需的少时间。
QCELP功率分析
如果将 ACM直接嵌入到下一代系统装置中去,它可以迅速地使其结构(其变换速度是如此之快,可以在一秒钟内变换数千次),适应多种算法的需要,使一台单纯的移动/无线电装置,能够执行并完成多种多样的功能与协议。ACM可以实现并形成,真正符合某一种算法所要求的硬件,不论要求的时间是长还是短,如果需要的话,可以按照时钟周期,以周期来实现。ACM与传统的IC技术(ASIC,DSP,微处理器,以及FPGA)相比,性能可以提高10倍到100倍,而功率消耗只需要一半,甚至仅为其十分之一。
这项技术可以达到的速度足够快,可以支持空分与时分的分段 (SATS, spatial and temporal segmentation),进一步显示出比传统IC技术的优越性。SATS技术,可以使动态的硬件资源,快速地执行某种算法的不同时间(temporal)段部分;和ACM自适应线路阵列(matrix)中,处于不同地域(spatial )的部分。一个由 SATS驱动的ACM,可以显着地减少QCELP语音压缩算法的功率消耗。
在DSP芯核上运行QCELP算法消耗大约84mW功率(图5)。这是根据0.25μm CMOS基具有DSP功能和存储器的片上系统大约占据4mm2,功耗84mW.相反,把8个功耗的QCELP算法放到ASIC逻辑芯核,其功耗只有19mW,即ASIC芯核功耗3mW,DSP芯核16mW.但这种设计方法占23mm2硅片。其中ASIC芯核运行8个内部码环路,而DSP芯核运行其余QCELP码。
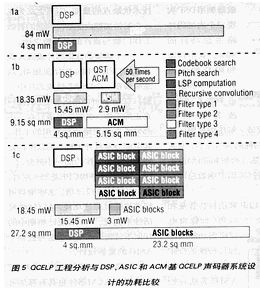
当便携系统设计人员把ACM加到DSP引擎以运行QCELP算法时,可大大减少功耗,这样做只增加5mm2 ACM芯片。在该设计实例中,8个功耗的程序从DSP运算中去掉,而加入功耗小的ACM引擎,只消耗3mW功率。采取这种设计步骤,节省了DSP运算的68mW(前面提及功耗为84mW)。现在,DSP/ACM基QCELP声码器总功耗只有19mW.
算法可编程ACM器件具有ASIC的功率特性,而大小可与DSP相比。ACM被列举进行任何时候特殊算法所需的硬件中,如本例中的8个内部码环路。每20ms,数据进入QCELP话音编解码器,所以每个内部码环路必须运行50次/秒。实质上,ACM是一片小的时限硅片,看起来像一个ASIC.结果以每秒运行400次,ACM形成运行这些算法所需的硬件。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。