假设我们正在设计一款包含一个或多个处理器内核的片上系统 (SoC) 设备。我们将在设备内部包含相对少量的内存,而大部分内存将驻留在 SoC 外部的分立设备中。
快的存储器类型是 SRAM,但每个 SRAM 单元需要六个晶体管,因此 SRAM 在 SoC 内部很少使用,因为它消耗大量空间和功耗。相比之下,DRAM 每个单元只需要一个晶体管和电容器,这意味着它消耗的空间和功耗要少得多。因此,DRAM 用于在 SoC 之外创建大容量存储设备。尽管 DRAM 提供高容量,但它的速度明显慢于 SRAM。
随着用于开发集成电路的工艺技术的发展,结构越来越小,大多数设备变得越来越快。遗憾的是,作为 DRAM 的晶体管电容器位单元却并非如此。事实上,由于其模拟特性,位单元的速度几十年来基本保持不变。
话虽如此,从外部接口来看,DRAM 的速度在每一代新产品中都翻了一番。由于每次内部访问都相对较慢,因此实现这一点的方法是在设备内部执行一系列交错的访问。如果我们假设我们正在读取一系列连续的数据字,那么接收个字将需要相对较长的时间,但我们会更快地看到任何后续的字。
如果我们希望传输大块连续数据,这种方法很有效,因为我们在传输开始时进行性命中,之后后续访问就会高速进行。然而,如果我们希望对较小的数据块执行多次访问,就会出现问题。在这种情况下,我们不是性点击,而是一遍又一遍地接受该点击。
速度更快
解决方案是使用高速 SRAM 在处理设备内部创建本地缓存存储器。当处理器首次从 DRAM 请求数据时,该数据的副本将存储在处理器的高速缓存中。如果处理器随后希望重新访问相同的数据,它会使用其本地副本,这样访问速度会快得多。
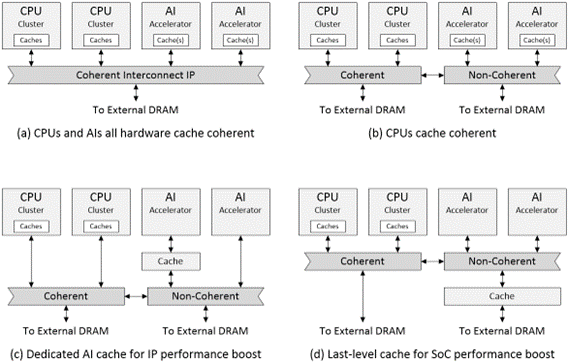
在 SoC 内部使用多级缓存是很常见的。这些级别称为 1 级 (L1)、2 级 (L2) 和 3 级 (L3)。级高速缓存的容量,但访问速度,随后的每都具有较高的容量和较低的访问速度。如图1所示,假设系统时钟为 1 GHz 且采用 DDR4 DRAM,则处理器访问 L1 缓存只需 1.8 ns,访问 L2 缓存只需 6.4 ns,访问 L3 缓存只需 26 ns。从外部 DRAM 访问一系列数据字中的个数据需要花费 70 纳秒(数据来源Joe Chang 的服务器分析)。

免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。