内存层次结构中的缓存
CPU 内部的寄存器数量相对较少,但速度极高。CPU 可以在单个时钟周期内访问这些寄存器。然而,它们的存储容量很小。相反,访问主
存储器以读取或写入数据会占用许多时钟周期。这通常会导致 CPU 大部分时间处于空闲状态。
1965年,英国计算机科学家Maurice Wilkes提出了高速缓存和内存缓存的概念。这涉及到与 CPU 相邻的少量快速内存(称为高速缓存)。“高速缓存”一词本身源自法语单词“cacher”,意思是“隐藏”或“隐藏”,其含义是高速缓存向 CPU 隐藏主存储器。
该过程基于两个关键点进行操作。首先,当CPU上运行的程序执行涉及主存储器中的一个位置的操作时,它通常会在多个附近的位置上执行操作。因此,当CPU从主存请求单个数据时,系统会从附近的位置引入数据。
图 1展示了涉及简单高速缓存的内存层次结构的视图。
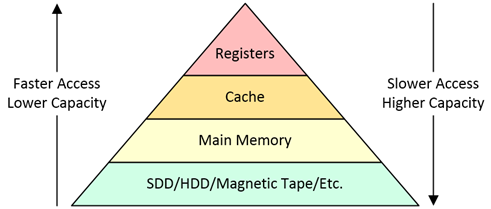
图 1视图显示了缓存在内存层次结构中的位置。动脉
这种方法可确保在需要时可以随时获取相关数据。其次,程序通常对同一数据集执行大量操作。因此,将活跃使用的数据存储在距离CPU近的缓存中是有益的。这种邻近性允许更快地访问和处理数据。
SoC 上下文中的缓存
对于 SoC,缓存在片上高速、高功率、低容量 SRAM 中实现。同时,主存储器在 PCB 上以片外方式实现,通常采用低速、低功耗、大容量 DRAM 的形式。
为了限度地减少延迟,设计人员在当今的许多 SoC 中添加了多层缓存。这些通常包括三个级别:L1、L2 和 L3。L1缓存距离CPU近,容量,但访问时间快,通常在1-2个时钟周期内。L2 缓存距离 CPU 稍远,提供更高的容量,但访问时间较慢,通常在 4-10 个时钟周期之间。L3 缓存距离 CPU 仍较远,提供三者中的容量,但访问时间慢,为 10-30 个时钟周期。
多个缓存级别可限度地提高性能,同时限度地减少对主内存的片外访问。访问该主存储器可能会消耗数百个时钟周期。通过使用多个缓存级别,可以更快地从这些缓存而不是较慢的主内存中检索数据,从而提高整体系统效率。
当涉及多个 CPU 时,所有这些的复杂性都会增加。考虑一个由四个 CPU 组成的集群的常见场景,标记为 0 到 3,每个都有自己的专用 L1 缓存。在一些实现中,每个还将有自己专用的 L2 缓存,而所有四个共享一个公共的 L3 缓存。在其他设计中,内核 0 和 1 共享一个 L2 缓存,内核 2 和 3 共享另一个 L2 缓存,并且所有四个内核共同使用相同的 L3 缓存。这些不同的配置会影响跨不同缓存级别存储和访问数据的方式。
通常,单个集群中的所有处理器都是同类的,这意味着它们是相同的类型。然而,拥有多个处理器集群正变得越来越普遍。在许多情况下,不同集群中的是异构的,或者是不同类型的。例如,借助 Arm 的 big.LITTLE 技术,“大”内核旨在实现性能,但使用频率较低。
“LITTLE”内核针对功率效率进行了优化,但性能较低,并且大部分时间都在使用。例如,在基于 Arm 的
智能手机中,“大”内核可能会被激活来执行 Zoom 通话等相对不常见的任务。相比之下,“LITTLE”内核可以处理更常见、要求不高的任务,例如播放音乐和发送短信。
维护缓存一致性
在具有单独高速缓存的多个处理元件共享同一主存储器的系统中,可能具有共享数据的多个副本。例如,一份副本可能位于主存储器中,而更多副本则位于每个处理器的本地高速缓存中。维护缓存一致性要求对一份数据副本的任何更改都反映在所有副本中。这可以通过用新数据更新所有副本或将其他副本标记为无效来实现。
缓存一致性可以在软件控制下保持。然而,软件管理的一致性很复杂并且调试起来具有挑战性。尽管如此,它仍然可以使用诸如缓存清理之类的技术来实现,其中存储在缓存中的修改数据被标记为脏数据,这意味着它必须被写回主存储器。缓存清理可以在整个缓存上执行,也可以在特定地址上执行,但这会占用 CPU 周期,并且必须在保存数据副本的所有 CPU 上执行。
保持缓存一致性的方法是使用专门的硬件来以软件不可见的方式管理缓存。例如,与处理器集群中的相关联的高速缓存通常包括维持高速缓存一致性所需的硬件。
使用或不使用
SoC 由大量称为知识产权 (IP) 块的功能块组成。处理器集群就是这样的一个 IP 块。连接 IP 块的常见方法是使用 NoC。
在许多 SoC 设计中,处理器集群外部不需要一致性,从而允许使用非一致性或 IO 一致性 AXI5 或 AXI5-Lite NoC,例如 Arm 的 NI 或 Arteris 的 FlexNoC。然而,对于具有缺乏固有缓存一致性的多个处理器集群的 SoC 设计,或者在集成需要缓存一致性的第三方 IP 或自定义加速器 IP 时,需要一致的 NoC。示例包括使用 AMBA CHI 协议的 Arm 的 CMN 或使用 AMBA ACE 和/或 CHI 的 Arteris 的 Ncore。

图 2在上面的示例中,主系统采用相干 NoC 以及采用非相干 NoC 的安全岛。
在整个芯片上普遍应用缓存一致性可能会占用大量资源,并且对于特定组件来说是不必要的。因此,将缓存一致性隔离到芯片的子集(例如 CPU 集群和特定加速器 IP)可以更有效地利用资源并降低复杂性,如图2所示。像 Ncore 这样的相干片上网络在需要严格同步的场景中表现出色。同时,非相干互连(例如 FlexNoC)非常适合不需要严格同步的场景。