随着交通运输和经济的发展,越来越多的出行者需要考虑合理地选择出行方案。通常可供出行者选择的出行方案比较多,如何为出行者快速提供到达目的地的可行性出行方案,是现今旅游、交通运输等行业迫切需要解决的实际问题,同时也是学者研究的热点和难点之一。为了解决交通出行问题,研究人员提出了出行路径选择模型与算法。出行选择模型主要以换乘次数少与出行距离短为优化目标,其目的是寻找一条路径。因此出行路径选择模型中所涉及的多源交通数据量较大且关系复杂,目前多选择利用关系数据库存储出行路径选择模型中所涉及的交通基础数据。故对这些交通数据检索并终确定的出行方案需要大量时间,而目前大多数的交通出行方案的查询只是针对如飞机、火车或者汽车的这种单一的交通工具的点到点查询。
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库,它产生于距今五十年前,随着信息技术和市场的发展,特别是二十世纪九十年代以后,数据管理不再仅仅是存储和管理数据,而转变成用户所需要的各种数据管理的方式。数据库有很多种类型,从简单的存储有各种数据的表格到能够进行海量数据存储的大型数据库系统都在各个方面得到了广泛的应用。
1 路径选择模型
由于交通出行路径查询中涉及多源的交通数据较多,导致从出行者的起点到终点的出行方案很多。为了能够快速准确查询出可行的出行方案,本文采用了基于分层结构首尾协同的出行路径模型来快速准确查询可行的出行路线。该模型的基本思想就是同时从起点(S)和终点(T)查询中转站信息,直到找到匹配的可行方案。该模型的出行方案查询策略如图1所示。

该模型主要包括以下几个部分:(1)选用SQL Server存储的交通数据及该模型中所产生的中间数据;(2)同时从起点(S)和终点(T)查询中转站信息,然后再对中转站信息进行匹配和查询,直到找到可行出行方案;(3)比较给出可行出行方案。
该模型的具体描述如下:
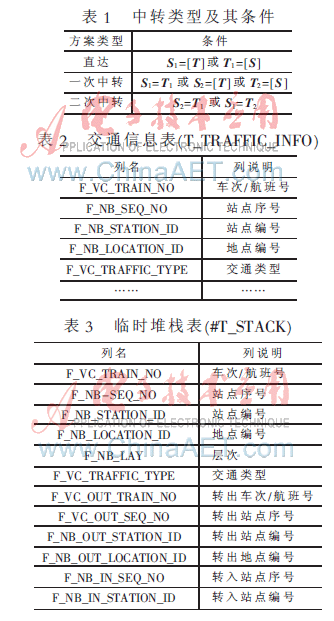
(1)利用SQL Server建立包括交通信息表、临时堆栈表、方案主表、方案子表和一些辅助临时表等一系列的关系数据表。SQL(STructured Query Language),结构化查询语言。SQL语言的主要功能就是同各种数据库建立联系,进行沟通。按照ANSI(美国国家标准协会)的规定,SQL被作为关系型数据库管理系统的标准语言。SQL语句可以用来执行各种各样的操作,例如更新数据库中的数据,从数据库中提取数据等。绝大多数流行的关系型数据库管理系统都采用了SQL语言标准。虽然很多数据库都对SQL语句进行了再开发和扩展,但是包括Select, Insert, Update, Delete, Create,以及Drop在内的标准的SQL命令仍然可以被用来完成几乎所有的数据库操作。
(2)从起点(S)开始向前查询出所有经过起点的交通信息集合。设这些信息集合为S1且层次为1;再以S1为起点向前查询经过S1的所有交通信息集合(不含同种交通工具的重复信息),设这些信息集合为S2且层次为2;则第i次搜索形成信息集合为Si且层次为i;经过若干次搜索后可将以起点为出发点以终点为目的的整个交通数据搜索完毕。
(3)从终点(T)开始向后查询出所有经过终点的交通信息集合。设这些信息集合为T1且层次为1;再以T1为起点向前查询出经过T1的所有交通信息集合,设这些信息为T2且层次为2,则第j次搜索形成信息集合为Tj且层次为j,经过若干次搜索后可将以终点为出发点以起点为目的的整个交通数据搜索完毕。
(4)比较Si中任意中转站集中任意和Tj中相同的中转站,找到从起点到终点的出行可行方案。基于分层结构首尾协同的两次以内中转出行路径查询算法的流程图如图2所示。
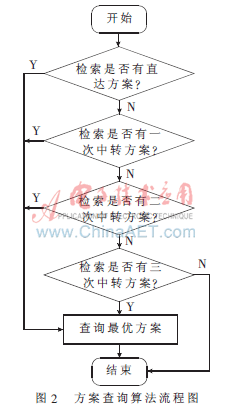
由图1可以得出如表1所示的直达、和二次转车出行条件。
2 算法实现
基于SQL Server的存储平台,设计了包含交通信息表(表2)、临时堆栈表(表3)、方案主表、方案子表和一些辅助临时表等用来存储路径选择过程中所涉及的数据。其中交通信息表格用来存储交通基础信息,该表中包括车次/航班号、站点序号以及站点编号等字段。临时堆栈表用来将每次查询出的车次信息按层次保存。SQL Server 是一个关系数据库管理系统。它初是由Microsoft、 Sybase 和AshtON-Tate三家公司共同开发的,于1988 年推出了个OS/2 版本。在Windows NT 推出后,Microsoft与Sybase 在SQL Server 的开发上就分道扬镳了,Microsoft 将SQL Server 移植到Windows NT系统上,专注于开发推广SQL Server 的Windows NT 版本。Sybase 则较专注于SQL Server在UNIX 操作系统上的应用。方案主表是方案子表明细的汇总,具体字段见表4.

3 应用与结果分析
首先,根据图2和表1确定中转车次数少的方案,根据方案查询出相应的信息,并将信息保存到临时堆栈表中(为解决同城多个站点中转问题,中转时使用地点编号作为中转条件);然后,生成可行的出行方案并保存到临时结果子表中;,对临时结果子表进行汇总并将结果保存到临时结果主表中。
3.1 临时堆栈表数据查询
临时堆栈表的数据是分层的,其S1和S2层是从起点查询的,T1和T2层是从终点查询的。其对应的表关联如下:
层:
T_TRAFFIC_INFO T1,T_TRAFFIC_INFO T2 Where
T2.F_NB_STATION_ID=(S) AND T1.F_VC_TRAIN_NO=
T2.F_VC_TRAIN_NO AND T1.F_NB_SEQ_NO>T2.F_NB_SEQ_NO
第二层:
T_TRAFFIC_INFO T1,#T_STACK T2,T_TRAFFIC_INFO T3 WHERE
T2.F_NB_LAY=1 And T2.F_NB_LOCATION_ID=
T3.F_NB_LOCATION_ID And T1.F_VC_TRAIN_NO
!=T2.F_VC_TRAIN_NO And T1.F_VC_TRAIN_NO=
T3.F_VC_TRAIN_NO And T1.F_NB_SEQ_NO>T3.F_NB_SEQ_NO
第三层:
T_TRAFFIC_INFO T1,#T_STACK T2,T_TRAFFIC_INFO T3 WHERE T2.F_NB_LAY=4 And T2.F_NB_LOCATION_ID=
T3.F_NB_LOCATION_ID And T1.F_VC_TRAIN_NO=T3.F_VC_TRAIN_NO And T1.F_NB_SEQ_NO<T3.F_NB_
SEQ_NO And T1.F_VC_TRAIN_NO!=T2.F_VC_TRAIN_NO
第四层:
T_TRAFFIC_INFO T1,T_TRAFFIC_INFO T2 Where
T2.F_NB_STATION_ID=(T) AND T1.F_VC_TRAIN_NO=
T2.F_VC_TRAIN_NO AND T1.F_NB_SEQ_NO<T2.F_NB_SEQ_NO
3.2 临时结果子表查询
在临时堆栈表数据的基础上,根据表1所对应中转类型的条件可直接获得此中转类型的所有方案数;再将具体的方案信息保存到临时结果表中(先保存到子表中,主表信息可根据子表的方案号进行汇总得到)。
3.3 结果分析
将起点、终点及其他参数作为存储过程的入口参数,通过参数便可获得相应出行方案信息,同时可根据策略对这些方案进行排序,从而获得出行者所需要的方案。
本文讨论了一种基于分层结构首尾协同的出行路径选择模型,通过对中转信息进行快速检索,并对相应信息判断是否匹配,以便找出相对优化的出行路径。但该算法仅适合起点(S)与终点(T)中都是有若干条线路途径的地点。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。