亚马逊 网络服务 (AWS) 正在推出其第四代 Graviton 处理器 Graviton4 芯片,该公司分享了这一消息。
亚马逊计算和人工智能产品管理总监拉胡尔·库尔卡尼 (Rahul Kulkarni) 表示,新芯片有望在性能和效率方面实现大幅提升,包括计算能力和内存比上一代产品高出三倍、内存带宽增加 75% 以及性能提高 30%。
库尔卡尼在位于德克萨斯州奥斯汀的亚马逊芯片实验室透露:“总的来说,它提供了更高的性价比,这意味着每花一美元,你都能获得更高的性能。”
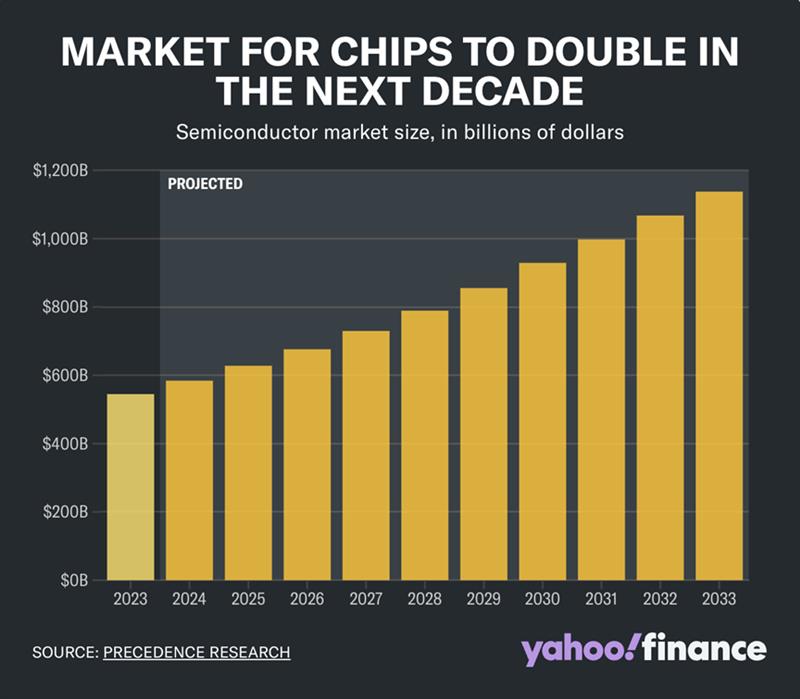
随着半导体继续在全球经济中发挥重要作用,为我们使用的几乎所有东西提供动力,对芯片的需求也在增长。该行业目前的价值为 5440 亿美元,预计到 2033 年将超过 1 万亿美元,这得益于对人工智能需求的不断增长。
因此,亚马逊、苹果、Alphabet 和微软等超大规模企业正在开发定制芯片,以满足他们的特定需求、降低成本并为客户提供更实惠的选择。
“所有这些公司都在芯片开发上投入大量资金,”在 AMD 担任副总裁十多年的帕特里克·穆尔黑德 (Patrick Moorhead) 表示。“他们不会谈论他们投资了多少,但他们的研发预算非常庞大。”
Nvidia仍然是 AI 芯片市场的主导者,在图形处理单元 (GPU) 市场占有超过 80% 的份额。但 Moorhead 表示,有足够的需求来支持多个竞争对手,他目前担任 Moor Insights & Strategy 的首席执行官兼首席分析师。
虽然 Graviton4 芯片不是 AI 芯片,但它支持专注于该技术的 AWS 的 Inferentia 和 Trainium 芯片。Trainium 与 Nvidia 的 AI 芯片直接竞争,后者被认为是市场上速度最快、性能最强大的芯片。
然而,Kulkarni 强调,AWS 的目标并不是取代 Nvidia。相反,这家云服务提供商希望为注重性价比的客户提供可行的替代方案,他们希望这能让他们从迅速扩张的人工智能芯片市场中分得一杯羹。
Kulkarni 表示:“目前,如果客户更注重上市时间,我们提供的基于 Nvidia 的产品是一个很好的选择。对于有些客户来说,成本是经营业务的一个非常令人望而却步的因素。如果他们想要进行更多成本优化的 AI 工作负载(如训练或推理),那么我们的 Inferentia 和 Trainium 产品将是一个很好的选择。”
除了从 Nvidia、AMD和英特尔等制造商购买芯片外亚马逊还自行设计芯片。AWS 目前提供两种主要芯片:专为 AI 设计的芯片和用于通用目的的芯片,例如 Graviton4。
在一次罕见的 AWS 实验室参观中,我们看到 AWS 工程师焊接和测试芯片设计,并使用软件查找性能问题并在现场修复。
该公司称这是降低开发成本的一种方法。
Kulkarni 表示:“我们可以调整产品、调整硅片,只关注对客户工作负载真正重要的事情。”
AWS 尚未披露 Graviton4 的具体定价细节,但这些处理器的租金为每秒 0.02845 美元。这种性价比对于 AWS 来说至关重要,因为它使用专有芯片为其云基础设施和服务器提供支持。
“AWS 客户可以使用 Graviton4 将 IT 费用减少一半,”Moorhead 表示。
AWS 的芯片战略不仅仅是向客户提供芯片,还利用其所有芯片产品来支持自身的努力,其中包括一个新的大型语言模型,这是 OpenAI 的 ChatGPT 的潜在竞争对手。
穆尔黑德指出,虽然芯片的开发成本很高,但从长远来看可以节省大量资金。
“假设你每年购买 100 万个芯片,每个芯片可以节省 200 美元,Moorhead 说。“积少成多,你就可以投入大量资金来实现这一目标。”
对于投资者来说,芯片开发的盈利预期可能比实际芯片生产对公司利润的影响更大。随着 AWS 希望通过设计、测试和验证其芯片来开拓自己的利基市场,分析师注意到该公司在半导体领域的影响力日益增强。
分析师对亚马逊的盈利预期高于微软或 Alphabet,仅 AWS 的利润率在 2024 年第一季度就达到了 38%。
“AWS 在半导体领域享有很高的信誉,”Moorhead说。“十年前,我曾质疑,当其他公司投资数十亿美元做芯片时,像这样的公司如何能做芯片。但他们在这方面非常擅长。”
AWS 对 GRAVITON 4 实例收取高额费用 几十年来,摩尔定律在服务器 CPU 性能和经济性方面的改进让我们所有人都认为,无论如何,随着每一代处理器的不断更新,我们总会看到单位性能成本的降低。但这并不总是发生,尤其是在 2020 年代晶体管尺寸缩小和时钟频率降低的末期。
亚马逊网络服务设计的 Graviton 4 处理器的市价显然没有发生这种情况,最初的 R8g 实例目前已普遍可用。最终,AWS 上将推出更多基于 Graviton 4 的实例,内存、本地存储和 I/O 容量各不相同,但目前基本 R8g 实例仅在四个地区可用。
Graviton 系列基于 Arm 的 CPU 由云巨头 Annapurna Labs 部门设计,其规模逐渐扩大,随着 Graviton 4 的推出,其能够承担更大的任务。该芯片具有更快的内核、更好的内核、更多的内核,并首次支持双插槽 NUMA 内存集群,从而带来 192 个以 2.8 GHz 运行的内核,并由 1.5 TB 的主内存支持。与目前可供出租的 Graviton 4 相比,2018 年 11 月推出的原始 Graviton 1 芯片看起来就像一个玩具。
AWS 于去年 11 月推出了 Graviton 4,当时并未透露有关该芯片的许多细节。Annapurna Labs 高级首席工程师 Ali Saidi 填补了我们显著特性表中的几个空白。Saidi 解释说,Graviton 4 芯片的运行速度为 2.8 GHz,非常接近我们猜测的 2.7 GHz。由于每个核心的 L2 缓存翻倍至 2 MB,AWS 团队得以减少处理器上的 L3 缓存量,从而为每个芯片的核心数量扩大 50% 至 96 个留下更多空间。事实上,每个核心的 L3 缓存已限制为 384 KB,比每个核心的 L2 缓存小 2.7 倍。但是,在那 96 个核心中,L3 缓存加起来共享 36 MB,并且比每个核心的 2 MB L2 缓存提供更大的共享内存空间。
“因此,每个 L2 都变得更大,也就是 2 MB,而不是 1 MB,”Saidi 告诉The Next Platform。“原因很简单。到达 L2 缓存需要 10 个周期,容量翻倍时需要 10 个周期。到达最后一级缓存需要 80 到 90 个周期。我们希望将尽可能多的内存放在尽可能接近的位置,我们将其设置为接近 8 倍。”
正如我们之前报道的那样,Graviton 4 基于Arm Ltd 的“Demeter” V2 内核,与 Nvidia 在其 72 核“Grace” CPU 中使用的内核相同,并且许多其他芯片制造商也选择使用这个内核。除了许多其他功能外,V2 内核还具有四个 128 位 SVE-2 矢量引擎,这对于许多 HPC 和 AI 工作负载非常有用。我们仍然不知道 AWS 为 Graviton 4 选择的工艺节点、这款产品上的晶体管数量、它拥有的 PCI-Express 5.0 通道数量或其热设计点。
但我们最终会了解这些事情。 AWS 在 33 个地区和 100 多个可用区部署了超过 200 万个 Graviton 处理器,它是 AWS 云的重要差异化因素,也是亚马逊集团(拥有不同的媒体、娱乐、零售、电子和云业务)的重要资源。事实上,假设 Graviton 4 实例与英特尔和 AMD 的大致相当的 X86 处理器相比,性价比高出大约 30% 到 40%(我们认为这次可能会高出 20% 到 25%,但需要查看一些跨架构基准才能做出更好的评估),我们看到的初始内存优化 R8g 实例的定价表明对 Graviton 4 的需求很高,高到购买它的客户可能会帮助母公司亚马逊以比其他方式少得多的价格获得自己的 Graviton 4 容量。
R8g 实例的单插槽内存从 1 到 96 个内核,从 8 GB 到 768 GB。网络带宽可按比例调整,每个实例最高可达 40 Gb/秒,弹性块存储 (EBS) 也最高可扩展到每个插槽 30 Gb/秒。我们认为双插槽 Graviton 4 实例是一个特殊情况,因为双插槽机器的网络带宽只有 50 Gb/秒,EBS 带宽只有 40 Gb/秒。此外,没有实例大小介于 96 和 192 个内核之间,如果亚马逊正在构建的所有物理机器都基于双插槽盒,那么你会期望有这样的实例。
再说一次,这可能只是 AWS 分配机器的方式。据我们所知,所有 Graviton 4 机器都可能是双插槽系统。很明显,AWS(以及其客户)重视跨处理器的 NUMA 内存共享,这是因为在 192 个内核和 1.5 TB 内存的情况下,这个节点可以运行相当大的工作负载,例如 SAP HANA 内存数据库,它将在 R8g 实例上获得认证。
AWS 计算和 AI/ML 产品组合产品管理总监 Rahul Kulkarni 表示,总体而言,从 Graviton 3 升级到 Graviton 4,客户应该可以预期性能至少会提升 30%,但在许多情况下,性能会提升 40% 甚至更高。这取决于工作负载的性质以及软件使用的整数或矢量特征。
AWS 为 Graviton 4 收取的溢价相当可观。让我们通过将 Graviton 4 R8g 实例与以前的 Graviton 2 和 Graviton 3 实例进行比较来看一下:
我们估计的 ECU(EC2 计算单元的缩写,这是 AWS 早期使用的一种非常古老的相对性能指标)将 Graviton 4 系列的性能提升至 Saidi 和 Kulkarni 所说的您应该期望的最低 30% 的性能提升。对于上面显示的这些实例,我们假设工作负载不受内存限制,并将相同的相对性能应用于每种 CPU 类型,而不管内存如何。在现实世界中,我们意识到,内存越多有时意味着您更接近计算引擎的理论性能。如果我们有更多数据,我们会估计较少内存对某些较小实例类型的性能影响。但我们没有更多数据。
为了获得相对性价比,我们按照 AWS 当前的定价估算了运行每个实例一年的成本。为了好玩,我们还估算了 R8gd 实例的成本,这些实例将像其他“gd”实例一样拥有专用的本地闪存存储。与往常一样,这以粗体红色斜体显示。
结果如下:如果将顶级 64 核 R7g 与顶级 96 核 R8g 实例进行比较,R8g 实例的性能提高了 30%,但成本提高了 65%,性价比降低了 26.9 %。
我们听到了过去 CPU 发布时发生过这种情况的回响。1990 年 IBM 的 ES/9000 大型机。2001 年 Sun Microsystems 的 UltraSparc-III 系统。2017 年的英特尔“Skylake”Xeon SP v1 处理器。所有这些处理器的单位性能成本都高于其前代产品,而且是在竞争即将变得激烈的特别艰难时期。我们怀疑,对于 AWS 来说,这更多的是关于根据市场承受能力定价。但这正是 IBM、Sun 和英特尔会说的话。事实上,他们当时都这么说过。我们当时就在那里。