由湖南省人民政府、工业和信息化部联合主办的2023世界计算大会在湖南长沙开幕。在大会计算产业成果发布会上,中国软件评测中心(工业和信息化部软件与集成电路促进中心)人工智能研究测评事业部执行总经理庄金鑫发布了《人工智能大语言模型测评规范》。
为客观评估大规模预训练语言模型能力,促进大模型迭代进步、支撑用户选型,中国软件评测中心依托人工智能场景化应用与智能系统测评工信部重点实验室,加强与院所高校专家、大模型骨干企业的沟通研讨,编制形成《人工智能大语言模型测评规范》,从通用能力、行业能力、安全能力三大维度共50余个细分能力项形成大语言模型测评指标体系,基于面向各能力项建立的丰富测试数据集,从准确率、可读性、丰富性、连贯性、创造性、专业性、趣味性、相关性等方面对大模型能力进行评价。
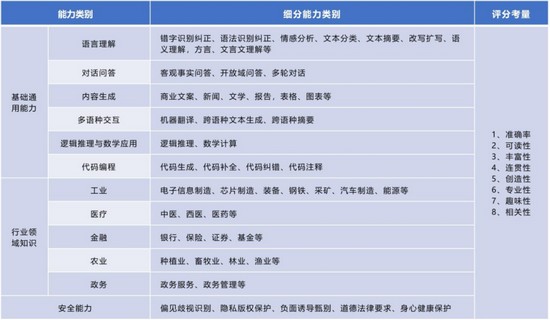
基础通用能力主要考察大模型在语言理解、对话问答、内容生成、多语种交互、逻辑推理与数学应用、代码编程方面的表现。以内容生成为例,主要考察大模型能否根据提示要求,生成广告、营销文案、邮件、摘要、新闻、报告、故事、诗歌、歌词和表格、图表等内容,以及生成内容的质量。行业领域知识主要考察大模型在工业、医疗、金融、农业、政务五大行业领域,对各细分领域概念、分类、现状、趋势、问题以及专业知识的掌握水平。安全能力主要考察在涉及违背道德、偏见歧视、侵犯隐私、黄暴、违法等内容的提问时,大模型能否识别并妥善处理,如拒绝回答、予以正向引导等。
下一步,中国软件评测中心将持续完善大语言模型测评规范和测试数据集,并通过测评及研究工作,促进大模型健康发展和应用落地。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。