全新CEVA-XC20延续了CEVA在数字信号处理器领域的行业领导地位。这款DSP架构采用新颖的矢量多线程计算技术,与前代产品相比,可将功率和面积效率提升多达2.5倍
这个高度可扩展DSP架构瞄准5G-Advanced eMBB设备、智能手机和蜂窝RAN设备的密集基带计算用例
全球领先的无线连接和智能感知技术及共创解决方案的授权许可厂商CEVA, Inc.(纳斯达克股票代码:CEVA)宣布推出第五代CEVA-XC DSP架构,是迄今为止效率最高的CEVA-XC20架构。
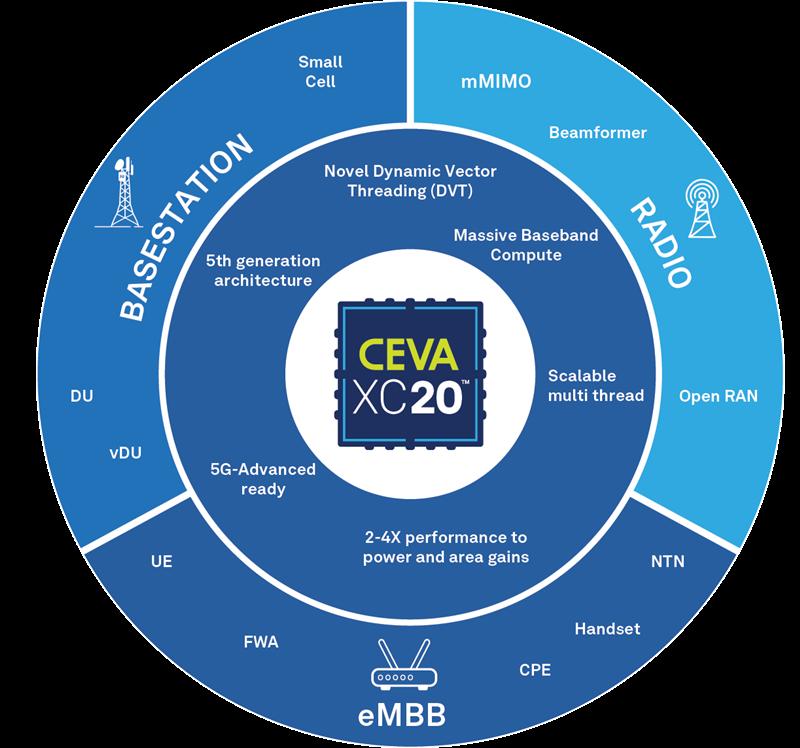
全新CEVA-XC20延伸了CEVA在DSP领域的领导地位,它基于突破性矢量多线程大规模计算技术,旨在应对智能手机、高端增强移动宽带(eMBB)设备(如固定无线接入和工业终端)和一系列蜂窝基础设施设备(如基站、虚拟化DU加速器,以及Massive MIMO无线电中的波束成形计算)等广泛使用案例中的下一代5G-Advanced <https://www.ceva-dsp.com/product/ceva-xc22/utm_source=PR&utm_medium=PRNewswire&utm_campaign=CEVA-XC22_230223>工作负载。借助CEVA-XC20架构,SoC和ASIC设计人员可以通过其业界领先的电源效率,设计出体积较小、功耗较低和更加环保的处理器产品,进而造福环境和社会。
ABI Research高级研究总监Dimitris Mavrakis表示:“CEVA的最新DSP架构提升了5G-Advanced蜂窝基带处理的性能和电源效率标杆,它采用独特的多线程方案,应对复杂5G场景中具有挑战性的电源、性能和面积限制。CEVA-XC20为任何开发自己的5G-Advanced硅芯片的无线半导体或OEM厂商提供了出色的解决方案,并且在帮助客户实现可持续发展目标的过程中发挥着关键性作用。”
CEVA与领先的一级OEM客户协商设计出CEVA-XC20架构,共同目标是改善移动网络性能和电源效率。CEVA-XC20采用新颖的动态矢量线程(Dynamic Vector Threading (DVT))方案解决了下一代计算密集型5G-Advanced应用所带来的性能难题。DVT方案支持真正的硬件多线程运作,到目前为止,这仅在通用CPU架构中出现。DVT实现了不同执行单元之间矢量资源的最佳共享,从而带来前所未有的矢量利用效率提升。这项技术达到了VLIW架构的最佳使用,提高了普通5G执行内核的核心效率,并显着增强了涉及多组件载体和多执行任务的用例。这样就可以增加矢量处理单元(这些单元通常在矢量DSP中占用大部分面积)的长度,同时保持甚至高于前几代内核的执行效率。
CEVA副总裁兼移动宽带业务部门总经理Guy Keshet表示:“5G-Advanced及更先进技术承诺不断增加蜂窝带宽并减低延迟,同时做到更环保、更节能。但这为需要实现这一承诺的无线设备企业和移动网络运营商带来了重大的挑战。我们最新的CEVA-XC20 DSP架构可以应对这些难题,充分利用CEVA在蜂窝DSP方面超过30年的丰富专业知识,可为最密集基带计算用例提供令人惊叹的更高电源效率。我们很荣幸能够与客户共同工作,不断改善蜂窝用户的使用体验,同时减低新技术对环境的冲击。”
第一款基于CEVA-XC20架构的DSP内核是CEVA-XC22 DSP,它使用突破性DVT方案支持两个执行线程。CEVA-XC22在基本5G用例和计算内核方面的效率(每瓦特性能和面积)相比其前代产品提高了2.5倍。CEVA还将CEVA-XC22集成到整体基带平台中,即用于蜂窝基础设施的PentaG-RAN平台和用于高性能移动设备的PentaG2-Max平台。其中,这款内核将推动这些CEVA异构计算平台,包括两个DSP和计算引擎加速器。
供货
CEVA将于今年第二季提供CEVA-XC22 DSP的普遍授权。CEVA-XC22客户还可以获得CEVA的Intrinsix团队提供ASIC/SoC共创服务带来的益处,以帮助整合和支持系统设计和调制解调器开发工作。如要了解更多的信息,请访问公司网页
<https://www.ceva-dsp.com/product/ceva-xc22/>。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。