在当今的音频处理领域,音频降噪是一个至关重要的研究方向。RNN(循环神经网络)在音频降噪方面展现出了独特的优势和巨大的潜力。下面我们将深入探讨 RNN 音频降噪背后的技术原理。
RNNoise 项目是将深度学习应用于噪声抑制的一个典型范例。其理念是巧妙地将经典的信号处理方法与深度学习相结合,从而打造出一个小巧、快速的实时噪声抑制算法。该算法具有显著的优势,它不需要昂贵的 GPU 支持,甚至在树莓派这样的小型设备上也能轻松运行。与传统的噪声抑制系统相比,RNNoise 算法不仅结构更加简单,调试起来也更加容易,而且在实际听觉效果上表现更为出色。
噪声抑制在语音处理领域是一个历史悠久的话题,早可以追溯到上世纪 70 年代。其思想是从带有噪声的信号中尽可能地去除噪声,同时将对语音内容造成的失真降到。传统的噪声抑制算法通常包含语音活动检测(VAD)模块和噪声谱估计模块。语音活动检测模块会判断当前信号中是包含语音还是只有噪声,并将这一信息传递给噪声谱估计模块,用于分析噪声的频谱特征。一旦了解了噪声的频谱特征,就可以尝试将其从输入音频中 “减去”,但实际操作远比听起来复杂。传统算法在各种噪声环境下难以稳定且高效地工作,需要对算法中的参数进行精细调试,并针对特殊信号编写专门的处理逻辑,这是一项既需要科学知识又需要实践经验的工作。
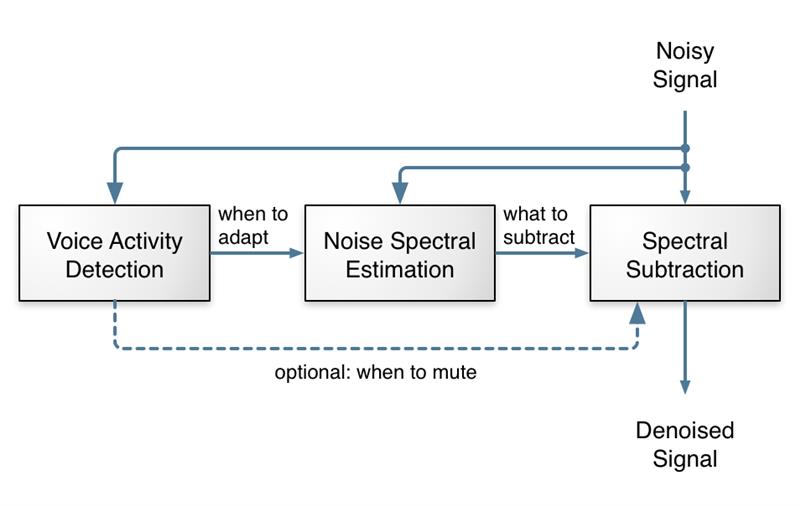
(图 1:传统噪声抑制算法概念图示)
深度学习是人工神经网络这一古老思想的现代版本。近年来,深度学习取得了显著的进展,主要体现在三个方面:一是能够构建超过两层隐藏层的深层网络;二是掌握了让循环神经网络(RNN)记住很久以前模式的方法;三是拥有了足够的计算资源来真正训练这些网络。循环神经网络在噪声抑制中尤为关键,因为它能够对时间序列进行建模,而不像传统方法那样将输入和输出帧看作彼此独立的。在很长一段时间里,RNN 的能力受到了限制,主要原因是无法长时间保存信息以及在 “时间上的反向传播” 时使用的梯度下降过程效率低,容易出现梯度消失问题。后来,门控单元的发明解决了这些难题,典型的门控结构包括长短期记忆网络(LSTM)、门控循环单元(GRU)等。RNNoise 使用的是 GRU,因为它在该任务上的表现比 LSTM 略好,且占用的资源更少。GRU 额外引入了重置门和更新门两个 “门控” 机制,能够更好地学习长期模式。
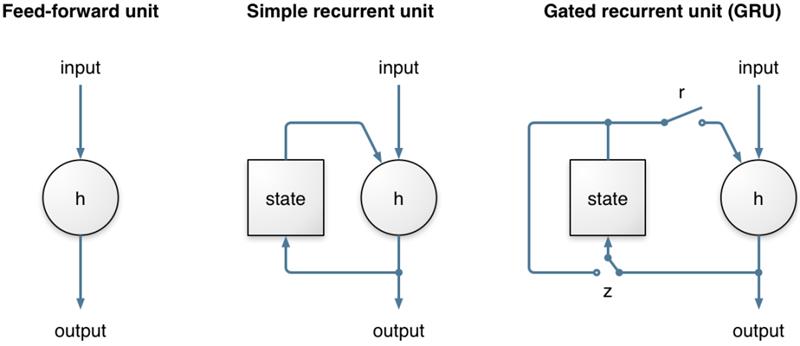
(图 2:简单循环单元与 GRU 对比)
如今,端到端的深度神经网络方法在语音处理领域越来越流行,但这种方法有时会显得效率低下,且在资源使用上较为浪费。RNNoise 采用了不同的方法,保留了基础的信号处理部分,只让神经网络学习传统信号处理中难调、易出错的部分。此外,RNNoise 关注的是实时通信,其前瞻时间仅为 10 毫秒,这对实时性能至关重要。
为了避免使用大量神经元,RNNoise 采用了按 Bark 频率尺度划分的频率带。这种尺度更符合人耳对声音的感知方式,终使用了 22 个频带,大大降低了神经网络的输出维度,同时保留了足够的音质信息。通过对频带进行重叠处理,在高频部分频带变宽,低频部分频带相对较窄。对于每个频带,计算一个增益值并应用到对应频带的信号上,就像一个 22 段的均
衡器,能够抑制噪声并保留有用的语音信号。这种 “按频带增益调整” 的方式具有模型简单、避免 “音乐噪声” 伪影、输出范围更安全等优点。在输入方面,同样使用 22 个频带的频谱信息,并对能量值进行对数计算和离散余弦变换处理,得到基于 Bark 频率尺度的倒谱特征。此外,还加入了前 6 个倒谱系数的一阶和二阶导数、音高周期、音高增益和非平稳性值等输入特征,共构成 42 个神经网络的输入特征。
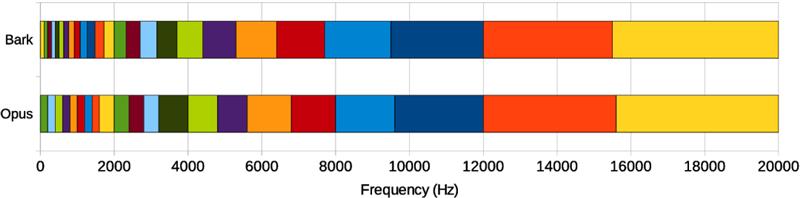
(图 3:Opus
编码器频带划分布局与 Bark 频率尺度对比)
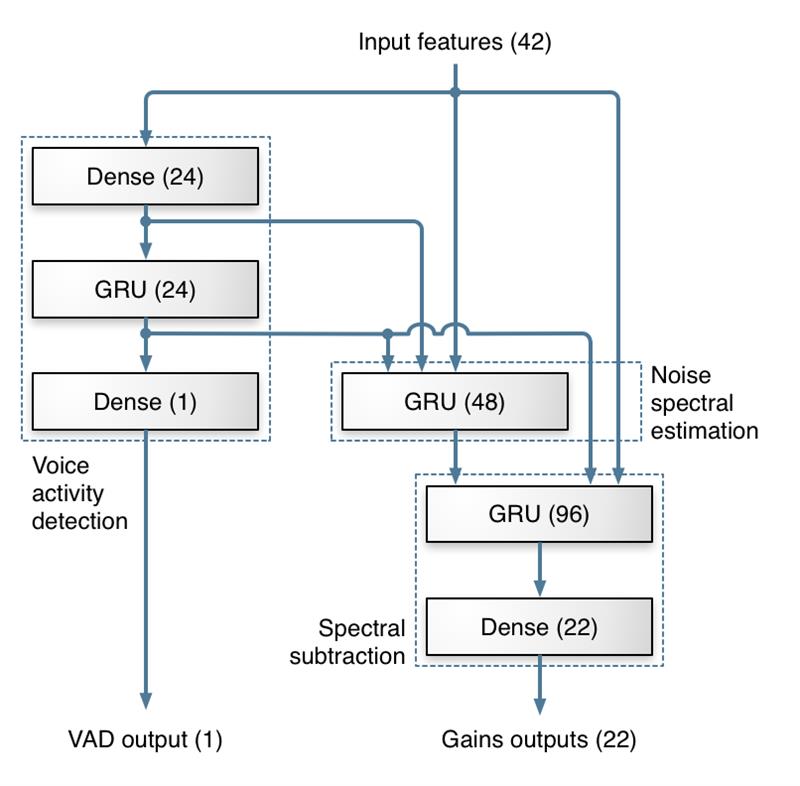
RNNoise 所使用的深度网络架构从传统噪声抑制方法中获得灵感,大部分处理工作通过 3 层 GRU 完成。网络有两个输出,一个是用于不同频率上的一组增益值,用于实现噪声抑制;另一个是语音活动概率,在其他应用中具有重要价值。实际测试表明,这种网络结构在效果上优于其他拓扑结构。
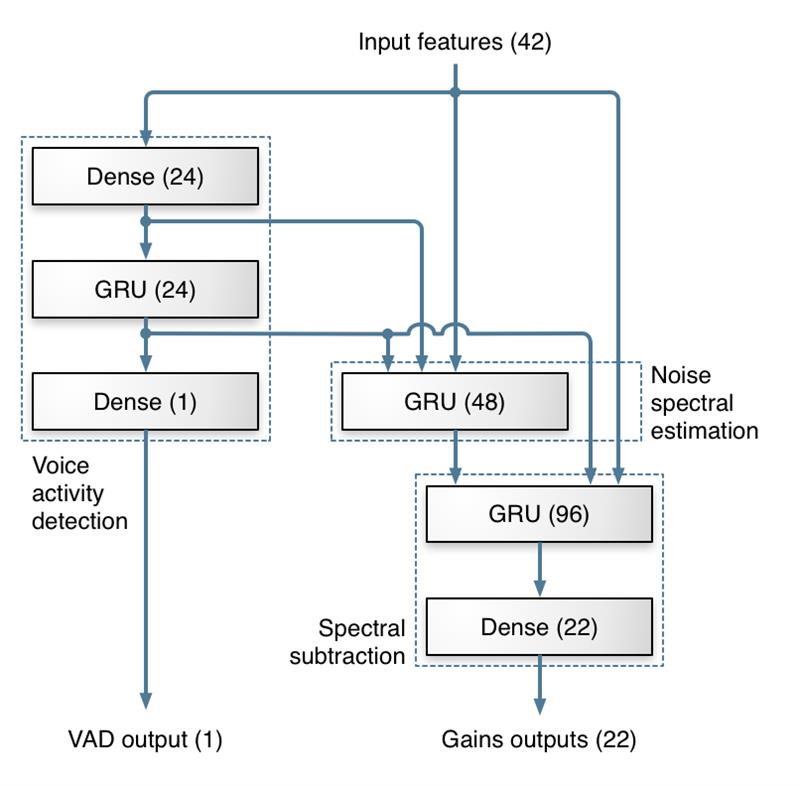
(图 4:神经网络拓扑结构图)
训练数据的质量对于深度神经网络至关重要。在噪声抑制场景中,由于难以直接收集用于监督学习的输入 / 输出数据,需要通过人工合成的方式构建训练数据。要收集足够多样化的噪声数据,并确保训练数据涵盖各种不同的录音条件。此外,RNNoise 没有对特征应用倒谱均值归一化,保留了代表音频能量的项,因此需要确保训练数据包含各种音量水平的音频,并对音频应用随机滤波,以增强系统对不同
麦克风频率响应的适应能力。
由于所使用的频带频率分辨率粗糙,无法细致地抑制音高谐波之间的噪声,RNNoise 通过基础的信号处理方法 —— 基音滤波来解决这个问题。以音高周期为间隔对采样点取平均,形成梳状
滤波器,保留音高谐波位置,衰减其间的频率分量。为了不扭曲语音信号,在每个频带上独立应用滤波,并根据当前帧的音高相关性和神经网络输出的频带增益值来确定滤波强度。目前使用的是 FIR 滤波器,未来也考虑使用 IIR 滤波器,以实现更强的噪声衰减效果,但需要注意避免信号失真。