新型 RISC-V 张量单元基于完全可定制的 64 位内核,声称与仅在标量
处理器上运行软件相比,可以为人工智能 (AI) 应用程序提供巨大的性能提升。张量单元通过硬件设计提供人工智能应用所需的矩阵乘法,在保持低能耗的同时提供强大的计算性能。
机器学习模型(例如 LLaMa-2 或 ChatGPT)包含数十亿个参数,需要每秒数万亿次操作的大量计算能力。这是因为大型语言模型 (LLM) 中的大部分计算都是构建为完全连接的层,可以通过矩阵乘法有效地实现。
Semidynamics 推出的张量单元提供了专门为矩阵乘法工作负载量身定制的硬件。它通过利用矢量单元功能以及该公司的 Gazzillion 技术从
内存中快速获取所需的数据来实现这一点。矢量单元通过 Gazzillion 技术不断馈送数据,确保没有数据丢失。
向量单元包含多个向量(大致相当于 GPU ),它们并行执行多个计算。每个矢量都具有能够执行加法、减法、融合乘加、除法、平方根和逻辑运算的运算单元。
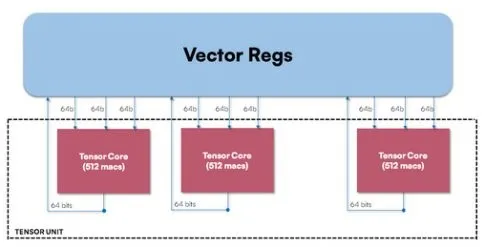
图 1 张量单元针对 64 位 RISC-V 内核进行了优化。资料半动力学
张量单元构建在公司的矢量处理单元之上,利用现有的矢量
寄存器来存储矩阵(见图1)。因此,它可用于需要矩阵乘法功能的层。此外,Tensor
Unit 可以将
Vector Unit 用于激活函数层,这相对于通常难以处理激活层的独立 NPU 来说是一个显着的改进。
Semidynamics 创始人兼执行官 Roger Espasa 表示,虽然其他解决方案依靠难以编程的直接内存访问 (DMA) 来解决这个问题,但他公司的解决方案将 Tensor Unit 无缝集成到其缓存一致性子系统中,开辟了一个新的解决方案。人工智能软件编程简单的时代。
此外,张量单元使用向量寄存器来存储其数据,并且不包含新的、架构上可见的状态。因此,它可以在任何支持 RISC-V 矢量的 Linux 下无缝工作,无需任何更改。
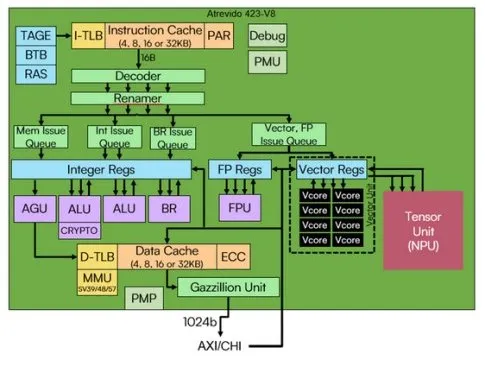
图 2这是包含 Atrevido-423 RISC-V 内核、Gazzillion 单元、向量单元和张量单元的整体整体。资料半动力学