当有人发现你在编教材的时候,会问下面两个问题。个是“你为什么写书?”第二个是“你的书和现有的书有什么不一样?”个问题相当容易回答。写书是因为你对现有的文本不完全满意。
在统计学和数据科学中,主成分分析(PCA)是非常重要的技术……但我在备课的时候,发现网上的资料过于技术性,不能完全满足我的需要,甚至提供互相冲突的信息。所以我很有把握地说,我对“现有的文本不完全满意”。
因此,我打算讲述下PCA的3W1H:什么是PCA(What),何时应用PCA(When),PCA如何工作(How),为什么PCA有效(Why)。另外,我也将提供一些深入解释这一主题的资源。我特别想要呈现这一方法的原理,其下的数学,一些实践,以及潜在的缺陷。
尽管我想要让PCA尽可能地平易近人,但我们将要讨论的算法是相当技术性的。熟悉以下知识能够更容易地理解本文和PCA方法:矩阵运算/线性代数(矩阵乘法,矩阵转置,矩阵取逆,矩阵分解,本征向量/本征值)和统计/机器学习(标准化、方差、协方差、独立、线性回归、特征选取)。在文章中,我加上了指向讲解这些主题的链接,但这些链接(我希望)主要起温习作用,以备遗忘,并不要求必须阅读。
什么是PCA?
假设你想要预测美国本年度的GDP。你具有大量信息:2017年季度的美国GDP数据,去年的GDP,前年的GDP……你有所有公开的经济指标,比如失业率、通胀率,等等。你有2010年的人口普查数据,可以估计每个行业中有多少美国人工作,以及在人口普查间隙更新这些估计的美国社区调查数据。你知道两党在参众两院各有多少席位。你可以收集股价、IPO数量,已经有多少CEO看起来对参政感兴趣。
TL;DR——有大量变量需要考虑。
如果你之前曾经处理过大量变量,你会知道这会带来问题。你了解所有变量之间的相互关系吗?你的变量是否多到导致过拟合风险显着加大?或者违背了建模策略的假设?
你也许会问:“我怎样才能仅仅关注收集变量中的一小部分呢?”用术语说,你想要“降低特征空间的维度”。通过降低特征空间的维度,你需要考虑的变量之间的关系不那么多了,过拟合的风险也不那么高了。(注意:这并不意味着再也不需要考虑过拟合等事项——不过,我们的方向是正确的!)
毫不令人意外,降低特征空间的维度称为“降维”。有许多降维的方法,但大部分降维技术属于:
特征消除
特征提取
顾名思义,特征消除(feature elimination)通过消除特征降低特征空间的维度。在上面举的GDP的例子中,我们可以保留三个我们认为能预测美国的GDP的特征,丢弃所有其他特征,而不是考虑所有特征。特征消除方法的优势有:简单,保持变量的可解释性。
特征消除方法的缺点是你无法从丢弃变量中获得信息。如果我们仅仅使用去年的GDP,制造业人口比例(根据的美国社区调查数据),失业率来预测今年的GDP,我们将失去所有丢弃变量的信息,这些丢弃变量本可以为模型贡献力量。消除特征的同时,我们也完全消除了丢弃变量可能带来的任何好处。
而特征提取没有这个问题。假设我们有十个自变量。在特征提取时,我们创建十个“新”自变量,每个“新”自变量是“旧”自变量的组合。然而,我们以特定方式创建这些新自变量,并根据它们对因变量的预测能力排序。
你可能会说:“哪里体现了降维?”好吧,我们保留所需的新自变量,丢弃“不重要的那些”。由于我们根据新变量预测因变量的能力排序,因此我们知道哪个变量重要,哪个变量不重要。但是——关键部分来了——由于这些新自变量是旧变量的组合,因此我们仍然保留了旧变量有价值的部分,尽管我们丢弃了一个或几个“新”变量!
主成分分析是一种特征提取技术——以特定的方式组合输入变量,接着在保留所有变量有价值部分的同时,丢弃“不重要”的变量!这还带来了有益的副作用,PCA得到的所有“新”变量两两独立。这是有益的,因为线性模型的假设要求自变量互相独立。如果我们用这些“新”变量拟合一个线性回归模型(见后文的“主成分回归”),这一假设必定会满足。
何时应该使用PCA?
你是否想要降低变量的数目,但不能够识别可以完全移除的变量?
你是否想要确保变量相互独立?
你是否可以接受让自变量变得不那么容易解释?
如果这三个问题的回答都是“是”,那PCA是一个很合适的选择。如果第三问的回答是“否”,那么你不应该使用PCA。
PCA是如何工作的?
下一节将讨论PCA为何有效。让我们在讲解算法之前先简要概括下整个过程:
我们将计算概括变量互相关性的矩阵。
接着我们将这一矩阵分为两部分:方向和大小。之后我们可以了解数据的“方向”及其“大小”(也就是每个方向有多“重要”)。下图展示了数据的两个主要方向:“红向”和“绿向”。在这一情形下,“红向”更重要。我们将在后文讨论这是为什么,不过,看看给定的数据点排列的方式,你能看出为什么“红向”比“绿向”更重要吗?(提示:能地拟合这些数据的直线看起来是什么样?)
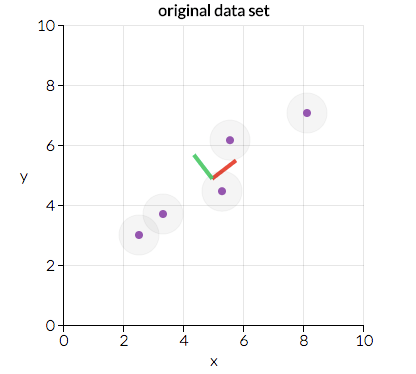
图片.io
我们将沿着重要方向(原变量的组合)转换原始数据。下图是经过转换的数据,x轴和y轴遵循“红向”和“绿向”。能地拟合这些数据的直线看起来会是什么样?
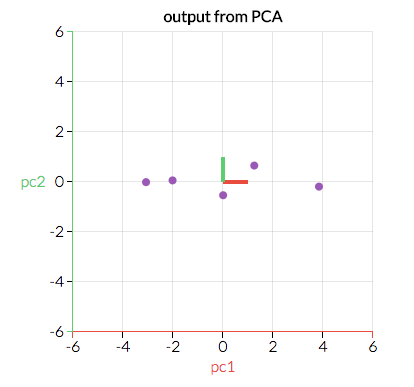
图片.io
尽管这里的可视化例子是二维的(因此我们有两个“方向”),我们可以设想数据具有更多维度的情形。通过识别哪些“方向”“重要”,我们可以通过丢弃“不重要”的“方向”将数据压缩进较小的特征空间。通过将数据投射到较小的特征空间,我们降低了特征空间的维度。但因为数据是根据这些不同的“方向”转换的,我们确保模型保留了所有原变量。
下面我将具体讲解推导PCA的算法。我尝试避免让本文过于技术性,但这里的细节不可能忽略,因此我的目标是尽可能明确地讲解。下一节将深入讨论为什么这一算法有效的直觉。
在开始之前,将数据整理成表格形式,n行,p+1列,其中一列对应因变量(通常记为Y),p列对应于自变量(这一自变量矩阵通常记为X)。
根据上一段的定义,将数据分成Y和X——我们主要处理X。
在自变量矩阵X的每一列上,从每个条目中减去该列的均值。(这确保每列的均值为0.)
决定是否标准化。给定X的列,是否高方差的特征比低方差的特征更重要?(这里重要指特征能更好地预测Y。)如果特征的重要性独立于特征的方差,那么将列中的每项观测除以该列的标准差。(结合第二步、第三步,我们将X的每列标准化了,确保每列的均值为零,标准差为1.)所得矩阵称为Z。
转置矩阵Z,将转置矩阵和原矩阵相乘。(数学上写为ZTZ.)所得矩阵为Z的协方差矩阵(无视常数差异)。
(这大概是难的一步——跟紧了。)计算ZTZ的本征向量和相应的本征值。在大多数计算软件包下,这都很容易做到——事实上,ZTZ的本征分解为将ZTZ分解为PDP-1,其中P为本征向量矩阵,D为对角线为本征值、其余值均为零的对角矩阵。D的对角线上的本征值对应P中相应的列——也就是说,D对角线上的个元素是λ1,相应的本征向量是P的列。我们总是能够计算出这样的PDP-1。(奖励:致对此感兴趣的读者,我们之所以总是能够计算出这样的PDP-1是因为ZTZ是一个对称正定矩阵。)
将本征值λ1,λ2…,λp由大到小排列。并据此排列P中相应的本征向量。(例如,如果λ2是的本征值,那么就将P的第二列排到。)取决于计算软件包,这可能可以自动完成。我们将这一经过排序的本征向量矩阵记为P*。(P*的列数应当与P相同,只不过顺序可能不同。)注意这些本征向量相互独立。
计算Z* = ZP*。这一新矩阵Z*不仅是X的标准化版本,同时其中的每个观测是原变量的组合,其中的权重由本征向量决定。一个额外的好处是,由于P*中的本征向量是相互独立的,Z*的每一列也是相互独立的!
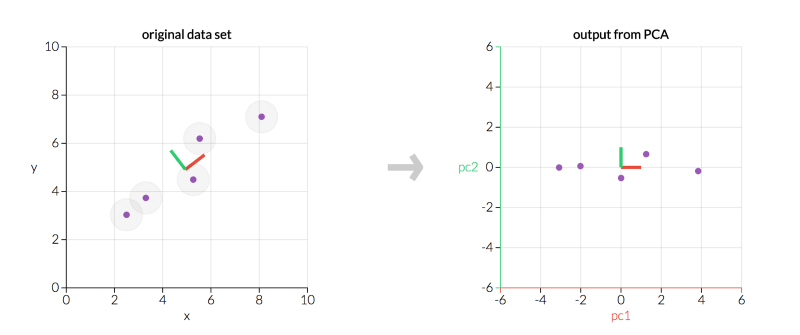
左为原数据X,右为经PCA转换后的数据Z*(图片.io)
上图中,有两点值得注意:
由于我们的主成分相互之间是正交的,因此它们在统计学上是相互独立的……这就是为什么Z*中的列相互独立的原因!
左图和右图显示的是同样的数据,但右图表现的是转换后的数据,坐标轴为主成分。
不管是左图还是右图,主成分相互垂直。事实上,所有主成分总是互相正交(正交是垂直的正式数学术语)。
,我们需要决定要保留多少特征,丢弃多少特征。决定这一事项有三种常见的方法,我们下面将讨论这三种方法并举例说明:
现在我们简单解释下解释方差比例这个概念。因为每个本征值大致等于相应本征向量的重要性,所以解释方差比例等于保留特征的本征值之和除以所有特征的本征值。
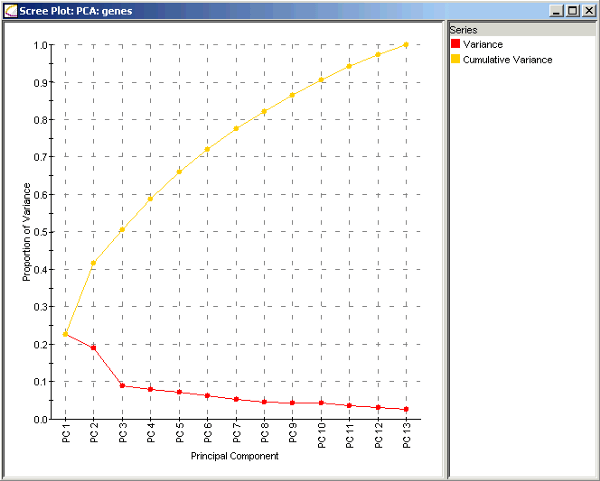
基因数据的陡坡图(.com)
考虑上面的基因数据的陡坡图。红线表明每个特征的解释方差比例,将该主成分的本征值除以所有本征值之和可以得到这一数值。仅仅包括主成分1的解释方差比例是λ1/(λ1 + λ2 + … + λp),约为23%. 仅仅包括主成分2的解释方差比例是λ2/(λ1 + λ2 + … + λp),约为19%.
包括主成分1和主成分2的解释方差比例是(λ1 + λ2)/(λ1 + λ2 + … + λp),约为42%. 也就是图中黄线的部分,黄线表明包括到该点为止的所有主成分的解释方差比例。例如,PC2处的黄点表明包括主成分1和主成分2可以解释42%的模型总方差。
下面,让我们看一些例子:
注意:有些陡坡图的Y轴是本征向量大小而不是方差比例。这样的陡坡图得出的结果是等价的,不过需要手工计算方差比例。
法一:假设我想保留模型中的5个主成分。在上面的基因数据例子中,这5个主成分可以解释66%的总方差(包括全部13个主成分的方差)。
法二:假设我想包括足够的主成分,解释90%的总方差。在上面的基因数据例子中,我将包括前10个主成分,丢弃3个变量。
法三:这次我们想要“找到肘部”。从上图中,我们看到,在主成分2和主成分3之间有解释方差比例的较大下降。在这一情形下,我们打算包括前两个特征,丢弃其余特征。如你所见,这个方法有一定的主观性,因为“肘部”没有一个数学上的定义,并且在这个例子中,包括前两个特征的模型只能解释42%的总方差。
法一: 随意选择想要保留多少维度。也许我想在二维平面上可视化数据,所以我可能只保留两个特征。这取决于用例,没有硬性规则。
法二: 计算每个特征的解释方差比例(下面将简要解释这一概念),选取一个阈值,不断加上特征直到达到阈值。(例如,如果你想要让模型可以解释80%的总方差,那就加上解释方差比例的特征,直到可解释的方差比例达到或超过80%.)
法三: 这一方法和法二密切相关。计算每个特征的解释方差比例,根据解释方差比例排序特征,并随着更多特征的保留,标绘出解释方差的累计比例。(这一图形称为陡坡图,见下。)根据陡坡图可以决定包含的特征的数量,在陡坡图中找到解释方差比例明显小于前一点的点,然后选择到该点为止的特征。(这个方法叫做“找肘法”,因为它通过寻找陡坡图的“弯曲处”或“肘部”以判定解释方差比例下降在何处发生。)
丢弃了我们想要丢弃的转换后的变量,就可以收工了!这就是PCA.
但是,为什么PCA有效?
尽管PCA是一个深度依赖线性代数算法的非常技术性的方法,仔细想想,它其实是一个相对直观的方法。
首先,协方差矩阵ZTZ包含了Z中每个变量和其他各个变量相关性的估计。这是一个了解变量相关性的强力工具。
其次,本征值和本征向量很重要。本征向量表示方向。设想下将数据绘制在一张多维的散布图上。每个本征向量可以想像成数据散布图的一个“方向”。本征值表示大小,或者重要性。更大的本征值意味着更重要的方向。
,我们做了一个假设,一个特定方向上的更多差异和解释因变量行为的能力相关。大量差异通常意味着信号,而极少差异通常意味着噪音。因此,一个特定方向上的更多差异,理论上意味着这一方向上有一些我们想要检测的重要东西。
所以说,PCA是一个结合了以下概念的方法:
变量之间的相关性的测度(协方差矩阵)。
数据散布的方向(本征向量)。
这些不同方向的相对重要性(本征值)。
PCA组合了预测因子,让我们可以丢弃相对不那么重要的本征向量。
PCA有扩展吗?
有,不过限于篇幅,这里不多说。常见到的是主成分回归,在Z*中未曾丢弃的特征子集上进行回归。这里Z*的相互独立发挥了作用;在Z*上回归Y,我们知道一定能满足自变量相互独立这一点。不过,我们仍然需要检查其他假设。
另一个常见的变体是核PCA,即先使用核函数升维,再使用PCA降维,从而将PCA应用于非线性情形。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。