
机器学习正快速成为物联网(IoT)设备不可分割的特征。家用电器开始装备可以智能地回应自然语音的语音驱动接口。机器人开始通过智能手机相机上的演示视频学习如何在工厂车间移动材料并为其他机器编程……
如何优化功率、性能和面积
机器学习正快速成为物联网(IoT)设备不可分割的特征。家用电器开始装备可以智能地回应自然语音的语音驱动接口。机器人开始通过智能手机相机上的演示视频学习如何在工厂车间移动材料并为其他机器编程。同时,智能手机变得更加智能。这些应用都充分利用了迄今为止为成功的复杂多维数据人工智能体系结构——深度神经网络(DNN)。
智能进入前端设备
到目前为止,嵌入式系统DNN技术应用的一个难题一直是它对计算性能的高要求。在输入数据被传递到经过训练的DNN进行识别和分析的推理阶段,需要的运算量虽然比训练阶段少,但语音、视频等流数据仍然需要每秒数十亿次计算。因此,在很多情况下,处理被转移到有足够运算能力的云端。但对于前端设备,这并非理想的解决方案。
自动驾驶车辆和工业机器人等关键任务,需要利用DNN实时识别物体的能力来提高态势感知。但云计算存在延迟、带宽和网络可用性等问题。在此情况下,得不到云端实时响应的风险是用户无力承担的。
隐私是另一个问题。尽管消费者认为智能扬声器等设备提供的语音帮助服务很方便,但他们也越来越担心,如果他们的语音录音被定期转移到云端,可能导致个人信息的意外泄漏。随着配备摄像头的智能扬声器和可视机器人助手的出现,这类担忧将变得更加严重。为了安抚客户,制造商正在研究如何将更多的DNN处理功能迁移到前端设备。他们所面临的主要问题是DNN处理不适合传统嵌入式系统的架构。
常规嵌入式处理器不足以应对DNN处理
对于低功耗设备,基于CPU和GPU的传统嵌入式处理器无法有效地承担DNN工作负载。物联网和移动设备对功率和面积有非常严格的限制,而高性能对于实时DNN处理是必要的。电源、性能和面积三要素(简称PPA)必须实现化,才能应对当前的任务。
解决这些问题的一种方法是为可以访问芯片内置存储器阵列的DNN处理提供硬件电路引擎。这种方法的问题是开发人员需要高度的灵活性。每个DNN设计的结构都需要根据目标应用进行调整。为语音识别设计和训练的DNN的卷积、合并和完全连接层的组合将不同于视频用途的DNN。由于机器学习仍然是一项不断发展的新兴技术,面向未来的解决方案必须具有灵活性。
另一种常用的方法是给标准处理单元添加矢量处理单元(VPU),这可以确保更高效的计算以及处理不同类型网络的灵活性。但这仍然不够。对于DNN处理而言,从外部DDR存储器读取数据是相当耗电的任务。因此,为了确保整体解决方案,还必须考虑数据效率和内存访问。为了限度地提高效率、可扩展性和灵活性,VPU只是AI处理器所需的关键模块之一。
实现带宽和吞吐量
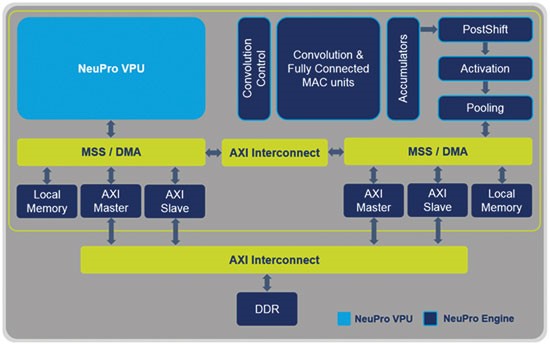
为了满足这些要求,CEVA创造了一种架构,它既可以满足DNN的性能挑战,又能保证处理各种嵌入式深度学习应用所需的灵活性。 NeuPro AI处理器包括经过优化的专用深度神经网络推理硬件引擎,用于处理卷积、完全连接、激活和合并层。此外,它还利用功能强大的可编程VPU来处理未支持层类型和推理软件执行。该架构与CEVA深度神经网络(CDNN)软件框架配套,该框架可以以图形化界面即时生成执行。

免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。