导读:本文介绍了软件无线电平台中基于FPGA的双缓冲模式PCIExpress(PCIE)总线的设计与实现。设计了基于XilinxVirtex-6FPGA的通用软件无线电平台,开发了基于Linux系统的驱动程序和PCIE硬核的DMA控制器。双缓冲提高了数据传输速度,节约了硬件资源。
引言
近年来软件无线电(SDR)得到了飞速的发展,在很多领域已显示出其优越性。本文的项目背景是通过软件无线电方式实现数字音频广播(DAB)的基带信号处理,这要求软件无线电平台具有高速实时数字信号处理与传输能力。高速可编程逻辑器件(FPGA)和丰富的IP核提供了能高效实现软件无线电技术的理想平台。
1 PCIE总线方案论证
PCIE是第3代I/O总线互联技术,如今已成为个人电脑和工业设备中主要的标准互联总线。与传统的并行PCI总线相比,PCIE采用串行总线点对点连接,具有更高的传输速率和可扩展性。例如本文采用的8通道1代PCIE 2.0硬核的理论传输速率是4 GB/s[1],其总线位宽亦可根据需求选择×1、×2、×4和×8通道。与其他的串行接口(如RapidIO和Hypertransport)相比,PCIE具有更好的性能和更高的灵活性[2].
1.1 PCIE总线实现方式
目前,PCI Express总线的实现方式主要有两种:基于专用接口芯片ASIC和基于IP核的可编程逻辑器件FPGA方案。前者通常采用ASIC+FPGA/DSP的组合方式,专用PCIE接口芯片(如PEX8311)避免用户过多地接触PCIE协议,降低了开发难度;但其硬件电路设计复杂,功能固定,灵活性和可扩展性较差。后者使用IP核实现PCIE协议,用户可以开发其所需的功能和驱动,具有可编程性和可重配置能力;另外,单片FPGA降低了成本和电路复杂程度,更符合片上系统(SoC)的设计思想。本文采用Xilinx公司Virtex6 FPGA和PCIE集成块,实现双缓冲模式的高速PCIE接口设计。
1.2 双缓冲与单缓冲比较
以写操作(数据从FPGA到内存)为例,双缓冲PCIE系统框图如图1所示。为描述方便,将该FPGA片上系统命名为SRSE(Software Radio System with PCI Express)。
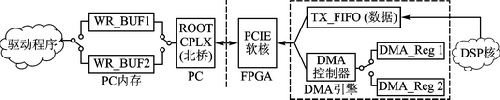
图1 双缓冲PCIE系统框图
PC端的驱动程序在系统内存上为SRSE分配了两个缓冲区(WR_BUF1/2)用于数据存储,这两个缓冲区的地址信息分别存储在FPGA端的DMA寄存器(DAM_Reg1/2)中。Root Complex连接CPU、内存和PCIE器件,它代表CPU产生传输请求[3]CIE核是Xilinx公司提供的集成块程序,实现PCIE协议的处理;DMA(直接存储器访问)引擎用于实现DSP核和PCIE器件间的高速数据存储与交换;DSP(数字信号处理)核是用户设计的算法或应用程序。以图1为例,DSP核将产生的数据写入TX_FIFO,DMA引擎将数据以传输层数据包(TLP)的形式发送至PCIE核,其中数据包的头信息来自寄存器DMA_Reg1.当SRSE将数据写入缓冲区WR_BUF1时,驱动分配另外一块缓冲区WR_BUF2并将该缓冲区的地址信息写入寄存器DMA_Reg2中;当DMA引擎发出WR_BUF1的写操作消息中断(MSI)后,DMA控制器将数据包的头信息切换至DMA_Reg2,驱动将缓冲区切换至WR_BUF2,继续传输数据。

图2 PCIE总线中断延迟测量
与双缓冲相对应的是单缓冲模式。以写操作为例,驱动程序每次在内存上分配一个缓冲区WR_BUF,该缓冲区的地址信息存储在DMA寄存器DMA_Reg中。当写满缓冲区WR_BUF时,DMA引擎会产生MSI中断,并通过PCIE核通知驱动程序。驱动分配新的缓冲区,并将该缓冲区地址通过PCIE总线写入DMA寄存器DMA_Reg中。中断的传输和DMA寄存器的更新会产生一定延时,这需要较大的TX_FIFO来存取延时期间DSP核产生的数据。
为测量中断延时时间,搭建了基于DELL T3400型PC和ML605开发套件的平台,通过ChipScope观察的波形结果如图2所示。DMA中断发生在时刻0(mwr_done:0﹥1);然后PCIE核向驱动发出MSI中断,驱动程序查询中断寄存器发生在时刻2241(irq_wr_accessed:1﹥0);驱动程序分配新的内存缓冲区,然后更新DMA寄存器发生在时刻2802(wr_dma_buff0_rdy:0﹥1)。在这2802个时钟周期内,PCIE器件无法将数据写入内存。PCIE的时钟频率为250 MHz,所以中断延时T=2802×(1/250 MHz)=11.2 μs.假定DSP核产生数据的速率为200 MB/s,中断延时期间将产生11.2 μs×200 MB/s=2241 B大小的数据。考虑到其他不可预测因素,如中断堵塞等,为了不丢失数据,TX_FIFO至少需要几KB的空间。这对于FPGA内宝贵的硬件资源(如Block RAM)来说是严峻的挑战。
与单缓冲模式相比,双缓冲模式优点归纳如下:
① 更新缓冲区不会引入中断延时,这意味着较小的FIFO即可满足需求,节约了硬件资源。
② 双缓冲模式延长了驱动程序处理中断的时间,也使缓冲区数据的处理更加容易,丢包率大大减小。
③ 数据的传输和内存缓冲区的数据处理可以并行处理,系统的实时性得到保证。
④ 双缓冲更适合Scatter/Gather DMA,取代block DMA,从而提高内存效率。
2 软件无线电平台设计
软件无线电基于可编程、可重构的通用硬件平台,通过加载不同的软件实现不同的无线电功能,广泛应用于军用和民用领域。为了能够实现复杂的算法,其平台需要具备高速数据交换和实时信号处理的能力。该设计参考Xilinx ML605开发套件,基于Xilinx Virtex6 LX240T FPGA芯片,通过增加相应的模块搭建通用的软件无线电平台。
软件无线电原理框图如图3所示。信号获取模块采用两片ADC和DAC以实现IQ两路信号的数模转换;通信模块由以太网和USBRS232接口组成;扩展卡可以是射频发射机或接收机,通过扩展卡接口与母板相连;JTAG接口提供在线编程和内部测试功能;存储器件包括512 MB DDR3内存和128 MB平台Flash,分别用于动态数据存储和配置FPGA;人机接口由LED/LCD、按键和开关等元件组成,实现人机对话;200 MHz有源晶振和SMA时钟接口组成时钟输入模块,向FPGA提供时钟基准;8通道PCIE接口和IP核实现平台与PC间高速数据交换。

图3 软件无线电原理框图
3 双缓冲模式PCIE总线设计
3.1 PCIE驱动设计
PC端基于Linux(Ubuntu 10.10)操作系统。该操作系统开源,安全稳定灵活,适合低成本软件开发。驱动程序包含数据流接口和控制接口。数据流接口用于Linux用户空间和SRSE平台间高速的数据交换;控制接口使用户可以观察和配置SRSE平台寄存器,例如通过控制接口,用户可以在PC端改变SRSE平台的调谐频率等参数。数据流接口是双向独立的,支持双/单工,即可以同时读和写数据。以数据发送(从PC到SRSE)为例,用户空间调用write()函数将任意数量的数据发送至驱动,驱动整理数据碎片以满足PCIE对数据对齐和传输块数据量的要求。当数据满足4096字节,驱动将数据块发送至Root Complex并保留已发送数据的列表,等待接收来自SRSE平台的写操作中断。PCIE驱动数据接收的原理如图4所示。当用户空间调用read()函数或者驱动接收到来自PCIE设备的数据时,驱动初始化读操作。驱动程序将保持阻塞(blocking),直到用户空间调用read()函数,并且已接收到足够的数据包,从而能够填满read()请求的数据量。碎片整理模块对已接收的数据进行整理,然后将数据块返回至用户空间,并通知其解除驱动阻止。

图4 PCIE驱动中的数据接收
3.2 PCIE核配置
Virtex6 PCIE Endpoint Block[4]集成了传输层(TL)、数据链路层(DLL)和物理层(PL)协议,它完全符合PCIE基本规范,可配置性增加了设计的灵活性,降低了成本。其功能框图与接口如图5所示。其中收发器通过PCIE总线与Root Complex实现数据包的传递,PCIE总线由系统接口和PCIE接口组成;系统接口由复位和时钟信号组成,PCIE接口由8条差分传输和接收对组成(8lane)。TX/RX Block RAM用来存储来自DMA引擎和系统内存的数据,其大小可以通过Xilinx Core Generator配置。传输接口为用户提供了产生和接收TLP的机制;物理层接口使用户能够观测和控制链路的状态;配置接口使用户能够观察和配置PCIE终端的配置空间,即DMA寄存器;中断接口实现DMA与PCIE核之间的中断传输。用户通过这些接口设计符合其需要的DMA引擎。

图5 PCIE功能框图与接口
本文使用Xilinx CORE Generator生成PCIE核,其主要配置参数如表1所列。

表1 PCIE核主要配置参数
3.3 总线主控DMA传输
参考Xilinx应用实例XAPP1052[5],本文设计的DMA结构框图如图6所示,各部分功能介绍如下:
① 发射引擎。发射引擎产生传输层数据包(TLP)并通过传输接口发送至PCIE核,数据包的数据来自TX_FIFO,头信息来自DMA控制/状态寄存器,也负责驱动对DMA寄存器的读取。
② 接收引擎。接收引擎将来自上位机的数据包解码并转存至RX_FIFO中,也接收来自驱动的配置信息并将寄存器值写入DMA控制/状态寄存器中。
③ DMA控制/状态寄存器。该模块是DMA的主控制器,控制着DMA复位、读写等操作;内存缓冲区的地址信息和TLP包长度等信息也存储在该寄存器中。
④ MSI中断控制器。该模块产生读写中断,然后通过中断接口通知PCIE核,进而通知驱动程序。
⑤ TX/RX_FIFO.通过Xilinx Core Generator将FIFO配置为独立时钟异步模式,实现不同时钟域的数据缓冲和位宽转换。本文PCIE时钟为250 MHz、位宽64位,而DSP核时钟为200 MHz、位宽32位。
⑥ PCIE核。该模块为例化的PCIE集成块,框图和参数详见图5和表1.
⑦ DSP核。该模块为用户设计的算法或者功能模块,例如通过Simulink调用Xilinx库实现某种功能。

图6 DMA结构框图
3.4 双缓冲PCIE协议
以写操作为例,双缓冲PCIE协议如图7所示。初始化时,驱动程序在内存中分配两块缓冲区Buff 1a/2a,然后将Buff 1a的地址信息写入DMA控制/状态寄存器DMA_Reg1(图1)中并开始写操作;DMA引擎将FIFO中的数据以数据包的形式通过PCIE总线发送至缓冲区Buff 1a中,期间驱动程序将Buff 2a的地址信息发送至DMA控制/状态寄存器DMA_Reg2中;当Buff 1a写操作完成时,MSI中断控制器产生MSI中断并通知驱动,此时驱动和DMA控制器同时切换缓冲区,即驱动将缓冲区切换至Buff 2a,DMA控制器将TLP头信息切换至DMA_Reg2,如此继续传输数据。

图7 双缓冲PCIE操作协议(写操作)
将MSI中断与新缓冲区配置间的时间间隔称为中断延时,如图2和图7所示。双缓冲模式的引入消除了中断延时的影响,使SRSE在中断延时期间仍能传输数据,节约了硬件资源,驱动程序也有更多时间来处理缓冲区的数据。
4 PCIE调试与性能
提供了Root Port的Test Bench,它可以模拟PC和驱动程序,如初始化DMA引擎、产生下行数据流并发送至PCIE设备,也可以接收来自PCIE设备的上行数据流等,使整个系统(PCIE核+DMA引擎+DSP核)可以在Modelsim SE环境下仿真。这大大缩短了开发周期,提高了开发效率。功能仿真通过后,使用Xilinx ISE 软件完成代码的输入、综合、实现、验证和。
硬件平台为DELL T3400型PC和Xilinx ML605开发套件。PC端基于Ubuntu 10.10操作系统运行驱动程序,FPGA端DSP核(图6)通过Matlab Simulink调用Xilinx元件库实现。本文DSP核由32位计数器和加法器组成:计数器将值写入TX_FIFO,PC端检测接收数据以验证写操作(SRSE→PC);同样地,PC端产生+1计数值并将数据写入RX_FIFO,DSP核的加法器用来验证读操作(PC→SRSE)。
结语
本文设计了基于Xilinx Virtex6 FPGA的通用软件无线电平台,利用C语言开发了基于Linux系统的驱动程序,利用Verilog语言设计基于Xilinx PCIE硬核的双缓冲DMA控制器。双缓冲消除了中断延时的影响,节约了硬件资源,提高了数据传输速度。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。