设计人员时常需要通过增加计算能力和/或额外输入的方式来延长现有嵌入式系统的寿命。在这方面,可编程系统平台大有用武之地。我们曾经希望采用安全网络连接功能来升级一套网络可编程系统。安全网络连接功能需要加密才能运行安全外壳(SSH)、传输层安全(TLS)、安全套接层(SSL)或虚拟专用网(VPN)等协议。这种安全需求伴随各种系统接入因特网的需求同步增长。
我们的系统基于Missing Link Electronics(MLE)公司的“软”硬件平台,其FPGA具有灵活的I/O,能够连接各种传感器和执行器。该平台采用可编程逻辑实现片上系统,以MicroBlaze CPU或PowerPC CPU作为其。CPU为操作系统与用户空间应用软件运行MLE Linux软件栈。由于采用MicroBlaze或PowerPC作为主CPU,当运行嵌入式Linux操作系统外加强大加密功能时,该系统显然无法提供所需要的计算性能,而且也无法改变物理硬件。
协处理硬件
可编程系统基本上是一个或几个CPU(运行操作系统与应用软件)的组合,外加一个FPGA。FPGA在其中用作灵活的接口“适配器”以及协处理硬件。我们可以根据FPGA器件和CPU之间的通信方式,采用不同方法调节系统性能和功能。
其中一种方法就是添加对等处理器,通过内存映射状态和控制寄存器与CPU实现同步。因为通过同一系统总线运行所有通信会很快降低性能,因此我们希望把CPU数据流与对等处理器分开。而采用赛灵思的Central DMA或多端口储存器控制器(MPMC)等片上系统组件能够轻松满足上述愿望。
另外,也可以增加一个协处理器,这种情况下能通过增加自定义指令(也叫编译功能)有效地扩展CPU的指令集。例如,它适合浮点单元,而且赛灵思的结构协处理器模块(FCM)技术能轻松支持上述功能。此处的优势是在CPU和协处理器之间使用一条从内存到系统总线的专用通信通道。对于PowerPC,其为辅助处理单元(APU),而对于MicroBlaze,则是快速单工链路(FSL)。
在加密和解密中,大部分运算按行或列执行,剩下四项运算并行计算,硬件对此任务得心应手。
AES:黄金标准
密码学中的加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法,是美国联邦政府采用的一种区块加密标准。这个标准用来替代原先的DES,已经被多方分析且广为全世界所使用。经过五年的甄选流程,加密标准由美国国家标准与技术研究院 (NIST)于2001年11月26日发布于FIPS PUB 197,并在2002年5月26日成为有效的标准。2006年,加密标准已然成为对称密钥加密中的算法之一。
AES的基本要求是,采用对称分组密码体制,密钥长度的少支持为128、192、256,分组长度128位,算法应易于各种硬件和软件实现。1998年NIST开始AES轮分析、测试和征集,共产生了15个候选算法。1999年3月完成了第二轮AES2的分析、测试。2000年10月2日美国政府正式宣布选中比利时密码学家Joan Daemen 和 Vincent Rijmen 提出的一种密码算法RIJNDAEL 作为 AES. 在应用方面,尽管DES在安全上是脆弱的,但由于快速DES芯片的大量生产,使得DES仍能暂时继续使用,为提高安全强度,通常使用独立密钥的三级DES。但是DES迟早要被AES代替。流密码体制较之分组密码在理论上成熟且安全,但未被列入下一代加密标准。
AES加密数据块和密钥长度可以是128比特、192比特、256比特中的任意一个。AES加密有很多轮的重复和变换。大致步骤如下:1、密钥扩展(KeyExpansion),2、初始轮(Initial Round),3、重复轮(Rounds),每一轮又包括:SubBytes、ShiftRows、MixColumns、AddRoundKey,4、终轮(Final Round),终轮没有MixColumns。
但是没有重大的系统重新设计,又该如何真正加速加密?对于加密,加密标准(AES)是一个事实标准。
采用AES加密时,无法通过定义减少计算任务,从而使嵌入式系统很快达到性能极限。如图1所示,其中显示用Valgrind分析工具、通过SCP(SSH会话)进行的文件传输的分析结果。此时AES加密占用三分之二计算任务。
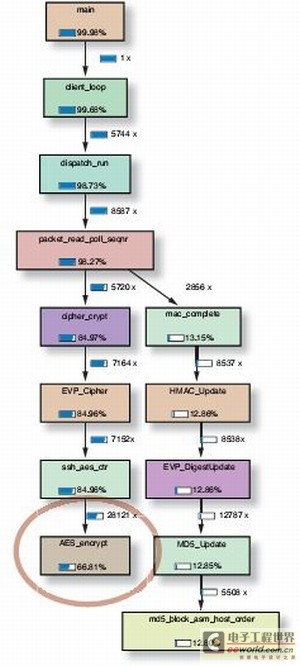
图1:在采用Valgrind工具的SCP传输中,AES加密占用三分之二的计算任务。
AES-128采用密钥和128位块大小,使用许多并发8字节运算。AES属于分组密码,基于按4x4字节阵列组织的固定分组大小运算。我们曾经采用128位分组大小,它能抵挡所有已知攻击,安全性甚至强于192位和256位版本。
一个回合稍有不同,因为其中省略了一些步骤。加密过程采用所谓的S盒(其提供非线性)执行替代。我们可以把它安置到一个16?16?8位矩阵中,从而能够适应常见的赛灵思BRAM原语。多个S盒实例可以加速IP核,并在适当的位置为内核提供所需数据,而无需等待对主存储器的长时间总线存取。解密过程大同小异,其采用相同密钥,但方向相反,并且使用不同S盒。
增速12倍
在加密和解密中,大部分运算按行或列执行,剩下四项运算并行计算—而硬件对此任务得心应手。这样就能够通过不同来源实现AES硬件的各个部分。为了加速系统,我们从庞大、快速增长的OpenCores.org资源库获取AES内核。
我们删除了原有的总线接口(因为它适用于另一种FPGA架构),另外为APU添加了一个接口,以便把AES内核作为FCM协处理器连接到PowerPC上。我们共使用8个所谓的UDI指令在PowerPC和AESFCM之间传输数据。
工作结果非常令人满意(见图2)。硬件加速的系统比原实现方案快了12倍。原来用以300MHz运行的独立的PowerPC加密一个单块需要17.8微秒,而采用以150MHz运行的AESFCM只需1.5微秒。如果只以升级到速度稍快的CPU来加速运算,我们采用硬件加速后的1.5微秒速度表现超过基于Intel Atom1.6GHz CPU的纯软件实现(其需要2.7微秒)。上述结果证明了使用FPGA技术的硬件加速的卓越潜能。
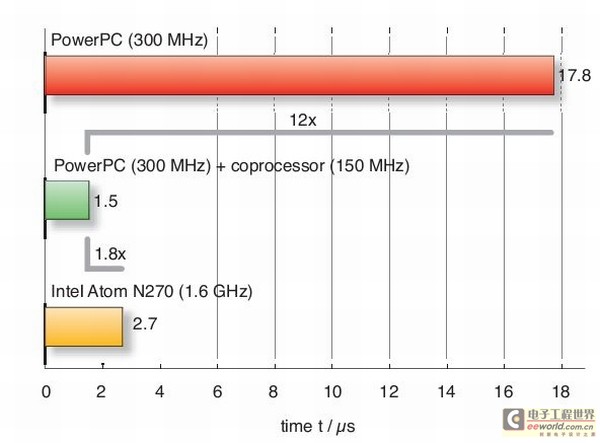
图2:硬件加速系统(中间绿条)快于独立的PowerPC或Atom处理器。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。