MIPS(Million Instructions Per Second):单字长定点指令平均执行速度 Million Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数。这是衡量CPU速度的一个指标。像是一个Intel 80386 电脑可以每秒处理3百万到5百万机器语言指令,即我们可以说80386是3到5MIPS的CPU。MIPS只是衡量CPU性能的指标。MIPS是世界上很流行的一种RISC处理器。MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlocked piped stages),其机制是尽量利用软件办法避免流水线中的数据相关问题。它早是在80年代初期由斯坦福(Stanford)大学Hennessy教授领导的研究小组研制出来的。MIPS公司的R系列就是在此基础上开发的RISC工业产品的微处理器。这些系列产品为很多计算机公司采用构成各种工作站和计算机系统。
一、MIPS指令集的限制
(1)所有指令长度都是32位:这意味着没有指令能够仅占用两三个字节的内存空间(因而MIPS的二进制文件比典型的680x0或80x86大百分之二十到三十),也没有指令可以超过四个字节。
随之而来就是不可能把一个32位常数放进单个指令中。MIPS设计者决定留出26位常数的空间用以编码跳转和调用指令的目标地址:但是仅有给两条指令。其它指令只能有16位空间留给常数。
(2) 指令操作必须适合流水线:只能在相应的流水线阶段才能执行任务,并且必须在一个时钟周期内完成。例如:寄存器写回阶段只能有一个值存入寄存器堆,所以指令只能修改一个寄存器。
(3)三操作数的指令:算数/逻辑指令不需要指定内存地址,所以空出了充足的指令位可以定义两个独立的源操作数和一个目的操作数。编译器喜欢三操作数指令,其给了优化程序更大的空间来处理复杂的表达式的代码。
(4)32个寄存器:寄存器数量的选择主要是由软件需求驱动的,在现代体系结构中一组32个通用寄存器是为流行的。采用16个肯定不够现代编译器的需要,但是32个足够让C编译器把常用的数据保存在寄存器中。
(5)寄存器零:$0寄存器永远返回零,给这个常用的数提供一个简缩的编码。
(6)没有条件码:MIPS的指令集的一个特征就是没有条件标志,这即使在1985年的RISC中也是极为激进的。许多体系结构有多个标志位来表示运算结果的“进位”、“为零”等等。CISC的典型做法是根据一些指令的操作结果设置这些标志,有些RISC体系结构保留了标志位。CISC是复杂指令系统计算机的简称,微处理器是台式计算机系统的基本处理部件,每个微处理器的是运行指令的电路。指令由完成任务的多个步骤所组成,把数值传送进寄存器或进行相加运算。复杂指令集计算机(Complex Instruction System Computer,CISC)早期的计算机部件比较昂贵,主频低,运算速度慢。为了提高运算速度,人们不得不将越来越多的复杂指令加入到指令系统中,以提高计算机的处理效率,这就逐步形成复杂指令集计算机体系。为了在有限的指令长度内实现更多的指令,人们又设计了操作码扩展。然后,为了达到操作码扩展的先决条件——减少地址码,设计师又发现了各种寻址方式,如基址寻址、相对寻址等,以限度地压缩地址长度,为操作码留出空间。
MIPS体系结构决定把所有信息保存到寄存器堆中。比较指令设置通用寄存器,条件分支指令检测通用寄存器。那样确实有利于流水线实现,因为能够减少对算术/逻辑操作依赖的巧妙机制不论从哪一种也都同时会减少比较/分支指令对中的依赖。
我们后边会看到有效的条件分支意味着是否分支的决定必须在半个流水线周期内作出:该体系结构通过保持分支决策的测试条件简单有助于实现这一点。所以MIPS的条件分支只测试单个寄存器的符号/为零或者一对寄存器是否相等。
二、寻址和访存
(1)访问内存只能通过简单的寄存器加载和存储:对内存变量进行算术运算会打乱流水线。,所以不这么做。每次内存访问都要一条显式的加载或存储指令……
(2)只有一种数据寻址方式:几乎所有的加载和存储都通过单个寄存器基址加上一个16位的常数偏移量寻址内存。
(3)字节地址指令:一旦数据存入MIPS CPU的寄存器,所有的操作都是在整个寄存器上操作。但是象C这样的语句语义不适合不能寻址内存到字节粒度的机器。因而MIPS对8-和16-位变量提供了一套完整的装入/存储操作。
(4)load/store必须对齐:内存操作只能从对齐到相应数据类型边界的地址加载荷存储数据。字节可以在任意地址传输,但是半字必须在偶数地址对齐,字在四字节边界对齐。
(5)跳转指令:有限的32为指令长度在想要支持很大程序的体系结构上对分支是个问题。MIPS指令的操作码域为6位,留出了26位来定义跳转的目标。因为所有指令在内存中都是四字节边界对齐的,低两位地址无需保存,这样可有256MB的地址范围。这个地址不是相对PC的,而是解释成256MB段内的地址。这对大于256MB的单个程序极为不便,到目前按还没有碰到太大的问题。
超出段内的分支可以通过使用一个寄存器跳转指令做到,该指令可以跳转任意32位地址。
条件分支只有16位的偏移域——给出了262144字节的范围,因为指令都是四字节对齐的——解释成相对PC的带符号的偏移量。如果知道分支目标会在紧跟分支之后的指令的128KB范围内,编译器就能只生成一个简单的条件分支指令。
三、MIPS没有的特性
(1)没有字节或半字数据的运算:所有算术和逻辑操作都是在32位的数据上进行。字节或半字的运算需要大量额外的资源和许多额外的操作码,而且很少有用。
然而当程序明确做short或者char运算时,MIPS编译器必须插入额外的代码以保证结果回绕和溢出,生成跟8-或16-位机器上一样的结果。
(2)没有对堆栈的特殊支持:传统的MIPS汇编确实定义了一个寄存器作为堆栈指针,但是硬件上SP没有任何特殊之处。有一种推荐的关于子程序调用的栈帧布局,这样可以混合不同语言和编译器的模块;你应当遵守这些约定,但是这些与硬件无关。
(3)少的子程序支持:有一点比较特别:跳转指令有一个跳转并链接的选项,把返回地址存入一个寄存器,默认是#31.所以方便起见习惯上用#31作为返回地址寄存器。
这样做比起把返回地址保存到堆栈上要简单,但却带来明显的好处。随便举两个好处瞧瞧:,保持了分支和访存指令的完全分离;第二,当调用许多根本不需要在堆栈保存返回地址的小程序时,这样做又助于提高效率。
(4)少的中断处理:很难看到硬件能做得比这更少的了。它把重新开始的地址存放到一个特殊的寄存器,接着仅修改刚刚够找出怎么回事的少量机器状态并禁止进一步中断,然后跳转到低端内存事先定义好的一个单一入口地址,伺候一切由软件负责。
(5)少的异常处理:中断只是异常的一种类型。一个异常可以来自一个中断,来自对物理上不存在的虚拟内存的试图访问、或者其它很多情况。一条有意引入的、类似系统调用的、用来进入受保护的OS内核的自陷指令发生时,也会进入一个异常。所有异常都导致控制传递到同样的固定入口地址。
按照约定,保留了两个通用寄存器给用于异常,这样异常处理程序可以自举。对于运行在允许中断和自陷的任何系统上的程序来说,这两个寄存器的值随时可能变化,所以不要用。
四、程序员可见的流水线效果
到目前为止,以上就是你需要从一个简化的CPU了解的全部内容。中央处理器(英文Central Processing Unit,CPU)是一台计算机的运算和控制。CPU、内部存储器和输入/输出设备是电子计算机三大部件。电脑中所有操作都由CPU负责读取指令,对指令译码并执行指令的部件。其功能主要是解释计算机指令以及处理计算机软件中的数据。所谓的计算机的可编程性主要是指对CPU的编程。 CPU由运算器、控制器和寄存器及实现它们之间联系的数据、控制及状态的总线构成。差不多所有的CPU的运作原理可分为四个阶段:提取(Fetch)、解码(Decode)、执行(Execute)和写回(Writeback)。然而使得指令集适应流水线也会导致一些奇怪的效果。
(1)延迟分支:MIPS CPU的流水线结构意味着当一个跳转/分支指令到达执行阶段产生新的程序计数器值时,跟在跳转指令后的指令已经开始了,该体系结构并不是丢弃这部分有潜在用途的工作,而是要求紧跟分支后的指令总是在分支目标指令之前执行。MIPS处理器是八十年代中期RISC CPU设计的一大热点。MIPS是卖的的RISC CPU,可以从任何地方,如Sony, Nintendo的游戏机,Cisco的路由器和SGI超级计算机,看见MIPS产品在销售。目前随着RISC体系结构遭到x86芯片的竞争,MIPS有可能是起初RISC CPU设计中的一个在本世纪盈利的。和英特尔相比,MIPS的授权费用比较低,也就为除英特尔外的大多数芯片厂商所采用。
要是硬件没有特殊处理,是否分支的决定以及分支的目标地址,就会在ALU流水阶段结束时得到——到此时,已经太晚了,甚至在下下一个流水线槽都来不及提供一个指令地址。
但是分支指令的重要性足以给予特殊处理。提供了一条经ALU的特殊路径可以让分支目标地址提早半个周期到达。连同取指阶段多出来的半个时钟周期的偏移,就刚好来得及去除分支目标指令作为下下一个指令。
编译器系统或者汇编程序应该考虑甚至利用分支延迟;结果是通常有可能通过适当安排使得延迟槽中的指令做些有用的工作。经常可以把别处的指令一道延迟槽中。
对于条件分支问题会有点复杂,分支延迟指令应当对两条分支路径都无害。实在找不到有用的事情可做时,延迟槽中填入一条nop指令。除非明确要求,否则许多MIPS汇编器都对程序员隐藏这个古怪的特性。
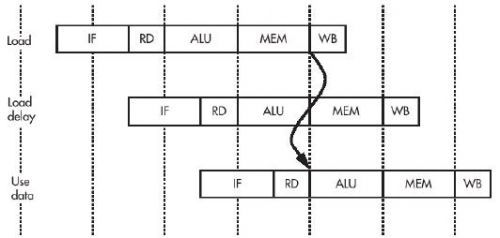
(2)数据加载延迟:流水线的另一个后果就是一条加载指令的数据在下一条指令的ALU阶段的开始才从高速缓存/内存系统到达——所以在下一条指令中不能使用加载的数据。
紧接加载指令后的指令位置称为加载延迟槽,一个优化的编译器将试图用它做些有用的事情。汇编器对程序员隐藏这一点,但可能插入一条nop指令。
在现代的MIPS CPU上,加载结果是互锁的:如果你试图过早使用结果,CPU将停下来等待数据到达。但是早期的MIPS CPU没有互锁,在延迟槽中试图使用数据将导致无法预料的结果。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。