随着互联网和万维网(World Wide Web)的快速繁荣发展,万维网逐渐成为人们生活中不可或缺的一种信息获取来源。万维网给信息检索技术带来了极大的机遇和挑战。经过近十几年的发展,信息检索已经由一个纯粹的学术研究学科转变成大多数人信息获取的技术基础。 随着Web 2.0概念的普及和发展,万维网不再仅仅是一个巨大的信息库,更逐渐成为一个用户参与和交流的平台。Web 2.0应用网站的蓬勃发展将再次推动信息检索技术的革新。在Web 2.0时代,信息检索技术主要有以下三方面的发展趋势:1)更加灵活的个性化信息服务。随着用户的急剧增加,Web 2.0网站迫切需要满足用户的个性化信息需求。然而,传统的Web信息检索技术并不擅长处理Web 2.0应用的复杂结构数据。Web 2.0需要更加灵活的个性化信息服务,如信息推荐系统。2)更加有效的多媒体数据检索技术。随着Web 2.0的普及,用户可以很方便地上传和分享多媒体信息。多媒体数据的迅速增多使得多媒体信息检索技术成为人们关注的焦点。
本文在传统向量空间模型的基础上提出一种新的检索方法,将N层向量空间模型应用在Web信息检索上,使之能较好地适应文档集合的动态扩充。理论分析和实验结果表明,此方法能够进一步提高向量空间模型的性能,节省存储空间,加快检索速度,具有较高的和召回率。
1 向量空间模型
1.1 传统向量空间模型
向量空间或称线性空间,是现代数学中的一个基本概念,是线性代数研究的基本对象。 向量空间是线性代数的主体,它是数学中基本又重要的概念,其概念是:设V为n维向量的集合,如果集合V非空,且集合V对于加法及乘数两种运算封闭,那么就称集合V为向量空间。其理论和方法已应用到自然科学、工程技术及社会科学的诸多领域。向量空间的一个直观模型是向量几何,几何上的向量及相关的运算即向量加法,标量乘法,以及对运算的一些限制如封闭性,结合律,已大致地描述了"向量空间"这个数学概念的直观形象。
向量空间模型的出发点是:每篇文档和查询都包含一些用概念词表达的、揭示其内容的独立属性,而每个属性都可以看成是概念空间的一个维数。因此,文档和查询就可以表示为这些属性的集合,从而忽略了文本结构中段落、句子及词语之间的复杂关系。这样,文档和查询可以分别用空间的一个点表示,并且文档矢量与查询矢量之间就存在空间上的不同距离,而这种距离关系在信息检索中的意义就是文档与查询之间的相似度。所以,文档与查询之间的相似度可以用矢量间的距离来衡量。相似度的计算方法有很多种,本文采用余弦系数法,即用二个矢量之间的夹角的余弦来表示文档与查询间的相关度。夹角越大,距离越远,余弦越小,相关度越小,反之相关度越大。下面介绍向量空间模型的量化方法。
tfij为特征项tj在文档di中出现的频率;dfj为在整个文档集中,包含特征项tj的文档数;idfj为反转文档频数,其值为:

可见,传统的向量空间模型是以文本特征项的频率tf和反转文档频率idf作为其量化基础的。其乘积作为特征项的权重,再通过计算文档与查询之间的相似度即可判断文档与查询是否相关。权重值大的特征项是那些在文档中出现频率足够高,但在整个文档集的其他文档中出现频率足够少的词语,也是对区别文档有意义的词语。
1.2 N层向量空间模型
将一篇文档从组织结构上划分为N层,基于每层的文本内容建立相应的特征项向量和权值。其中特征项抽取和权重计算等同传统向量空间模型相同。这样,对于文档进行N层划分得到的向量空间模型就成为N层向量空间模型。
本文针对Web信息检索进行考虑,由于Web页面的特殊格式,要求一篇文档少是由指向该文档的链接、文档标题和文档正文三部分组成。而这三部分的内容对于这篇文档的表达能力是不同的。链接的文字是吸引别人点击文档进行阅读的通道,所以链接的内容表达文档的能力强,其次是标题,正文的内容表达文档的能力弱。
因此,将N层向量空间模型应用在Web信息检索时,可将一篇Web文档按照指向文档的链接、标题和正文划分成3层(若Web页面中有<meta keyword>等标记的关键字部分,则可划分为4层向量空间模型。)。
2 应用N层向量空间模型进行Web信息检索
2.1 文本向量表示形式的改进
向量空间模型在建完索引以后,要根据每一个特征项求其对于每一篇文档和查询的权重值。其计算量非常大,并且每一篇文档和查询的向量表示式为![]() ,其中大多数项都为零,所以导致了数据稀疏现象。另外由于Web页面的超链性(hyperlink),页面上显示的信息有很多是和本页内容无关的,例如别的页面的链接、版权信息、栏目导航等,在每个页面上都有重复出现,这干扰了相似度计算。为解决这些问题,首先引入停用词表,例如文档中很多不能说明文档内容的语法词,还有虚词、感叹词、连词等或各个文档共有的词,所有这些词作为描述文档的向量效率是非常低的。因此可以考虑降维处理,把它们作为停用词,不计算其权重;其次,采用压缩矩阵的办法来解决数据稀疏问题,定义文档和查询的向量表示形式为:<……,(ti,ωdi),……>,其中ti为第i个特征项,ωdi为其对应的权重值且ωdi≠0.这样既减少了计算量,又加快了计算速度,同时节省了存储空间。
,其中大多数项都为零,所以导致了数据稀疏现象。另外由于Web页面的超链性(hyperlink),页面上显示的信息有很多是和本页内容无关的,例如别的页面的链接、版权信息、栏目导航等,在每个页面上都有重复出现,这干扰了相似度计算。为解决这些问题,首先引入停用词表,例如文档中很多不能说明文档内容的语法词,还有虚词、感叹词、连词等或各个文档共有的词,所有这些词作为描述文档的向量效率是非常低的。因此可以考虑降维处理,把它们作为停用词,不计算其权重;其次,采用压缩矩阵的办法来解决数据稀疏问题,定义文档和查询的向量表示形式为:<……,(ti,ωdi),……>,其中ti为第i个特征项,ωdi为其对应的权重值且ωdi≠0.这样既减少了计算量,又加快了计算速度,同时节省了存储空间。
2.2 特征项频率统计的改进
在统计每个区域的特征项频率得到tfij后,要乘以一个反映其重要程度的比例系数来加以修正和调整,则特征项tj在文档di中出现的频率为:
![]()
其中:tfiji为第i个区域的频率(i为1、2、3时分别对应链接区域、标题区域、正文区域),α>β>γ≥1为比例系数。
同样,在文档同一区域中,不同的特征项所表达文档内容的能力也是有差别的。例如同在正文区域的不同的特征项所代表文档的内容就有可能不同。在计算特征项频率tfij时再乘以一个比例因子log2(M/mi),其中M为该特征项在本文档中共出现的次数,mi为该特征项在文档第i次出现的次数。这样,特征项tj在文档di中出现的频率调整为:

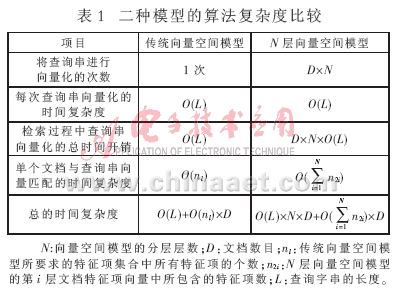
2.3 传统向量空间模型与N层向量空间模型的算法复杂度比较
表1为传统向量空间模型与N层向量空间模型的算法复杂度比较结果。
3 实验设置
(1)信息检索实验系统。信息检索实验系统选用了Smart系统。SMArt系统是基于向量空间检索模型实现的信息检索系统。在本实验中,为便于实现对向量空间模型算法的修改,使用的是经过修改的Smart信息检索系统。
(2)测试集。测试集分为文档和查询(query)二部分:文档部分采用新浪网站(www.sina.com.cn)的新闻部分Web版(32,145篇)。查询部分使用新浪网站的新闻讨论标题,共50个。
(3)评价方法。本系统使用和召回率来评价。是检索出来的相关文档数和检索出来的总文档数的比值;召回率是检索出来的相关文档数和总的相关文档数的比值。通常,召回率越高,越低;反之越高,召回率越低。所以有说服力的是11个点的平均。世界上权威的文本检索评测会议TREC(Text Retrieval Conference)的评测依据就是这个值。本系统将只提供这个值。
4 实验结果
这里对传统的向量空间模型算法和改进后的向量空间算法进行了比较,并统计了对应于每一条查询的11个点处的平均值。其结果如表2所示。

因为平均值仅仅是11个点处的值的平均值,为了进一步说明问题,图1给出了这几次检索的-召回率曲线。

从图1中可以看出,改进向量空间模型在索引时间和上都要优于传统向量空间,性能有了很大的提高。
本文提出了一种应用N层向量空间模型算法用于Web信息检索的办法。理论分析和实验结果表明,改进后的方法大大提高了Web信息检索的性能,节省了存储空间,加快了计算速度,具有较高的和召回率。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。