PDF417条码是一种高密度、高信息含量的便携式数据文件,是实现证件及卡片等大容量、高可靠性信息自动存储、携带并可用机器自动识读的理想手段。由于二维条码具有成本低,信息可随载体移动,不依赖于数据库和计算机网络、保密防伪性能强等优点,结合我国人口多、底子薄、计算机网络投资资金难度较大,对证件的防伪措施要求较高等特点,可以预见,PDF417条码在我国极有推广价值。二维条码在我国有着广阔的应用前景,PDF417条码技术在我国的推广应用必将为我国信息产业的发展和现代化的经济建设带来积极的影响。
本文介绍的解码终端采用专用条码摄像头采集条码图像,在基于TMS320C6713的DSP平台上实现了PDF417条码的准确、快速读取。
1 PDF417条码概述
二维条码PDF417做为一种新的信息存储和传递技术,从诞生之始就受到了国际社会的广泛关注。经过几年的努力,现已广泛地应用在国防、公共安全、交通运输、医疗保健、工业、商业、金融、海关及政府管理等领域。 美国亚利桑那州等十多个州的驾驶证、美国军人证、军人医疗证等几年前就已采用了PDF417技术。将证件上的个人信息及照片编在二维条码中,不但可以实现身份证件的自动识读,而且可以有效地防止伪冒证件事件的发生。菲律宾、埃及、巴林等许多国家也已在身份证或驾驶证上采用二维条码,据不完全统计,准备在身份证或驾驶证上采用二维条码PDF417的国家已达40多个,我国对香港地区恢复行使主权后,香港居民新发放的特区护照上采用的就是二维条码PDF417技术。

条码采用文本、字节和数字三种数据压缩模式将原始数据转换为0~928的码字。三种压缩模式分别对不用类型的数据具有较高的压缩率,三者之间用模式转换与模式锁存进行灵活的转换。
PDF417采用Reed-Solomon码对条码数据进行检错与纠错,别含有512个纠错码字,可复原条码50%的码字。
2 硬件平台
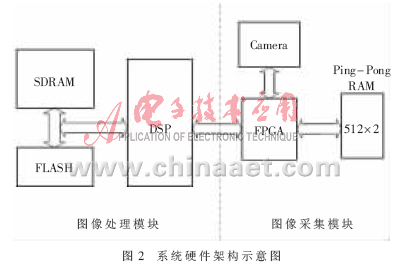
系统的硬件架构如图2所示。系统硬件主要包含图像处理和图像采集两个模块。
2.1 图像处理模块
系统的图像处理模块采用DSP外配SDRAM的方式实现图像的快速处理。DSP芯片选取TI公司的高性能32位浮点处理芯片TMS320C6713B;SDRAM芯片为Micron公司的MT48LC32M8A2,其存储空间为256 MB.C6713芯片的高速浮点处理能力保证了条空宽度确定的速度与准确性。系统工作过程中,SDRAM的作用为:缓存图像数据;存放图像运算的中间变量;作为系统的堆栈空间和常量及表的存放空间。
2.2 图像采集模块
视频数据采集模块由条码采集摄像头、FPGA和乒乓RAM 3个部分组成。摄像头采用Microscan公司的条码图像采集专用激光摄像头QUADRUS MINI Imager.由于TMS320C6713B芯片无video port接口,不能直接和摄像头进行逻辑连接,因而采用ALTERA公司的EP1C6作为控制,将Camera采集的视频信号流以帧为单位保存到高速SRAM中,并在合适的时机将SRAM总线切换给DSP以供运算处理。乒乓RAM以FPGA和DSP之间的通信接口RAM而存在,解决了DSP和摄像头连接的问题。另外,该模块还为摄像头配备LED补光系统以改善采集图像的质量。
3 软件设计
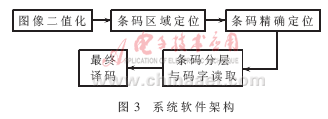
解码终端软件的设计强调提升条码识别率、解码正确率和系统实时性3个指标,主要包含二值化、区域定位、定位、条码分层等模块。图3为系统软件架构。
3.1 不均匀光照条件下的图像二值化
条码图像二值化要考虑不均匀光照的影响以及系统实时性解码的要求。本文改进了Bernsen算法[3],成功地去除了不均匀光照的影响。该算法处理步骤如下:
(1)用大津法取得粗阈值为T.扫描整个f(x,y)灰度图像,如果f(x,y)>T+a,则b(x,y)=255;如果f(x,y)<T+a,则b(x,y)=0.其中a为Bernsen算法的处理区间宽度,取值范围15~30,b(x,y)为二值化后图像。
(2)对发生光照不均匀严重的区域,即落在区间T-a<f(x,y)<T+a的点进行处理,取w为阈值计算窗口,计算方法如下:
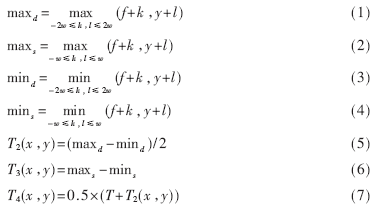
如果T3>a,则取T2为阈值;否则,取T4为阈值,对区间内的点进行二值化。
Bernsen算法只用T2作为阈值对区间内点进行二值化,忽略了全局阈值的作用,而改进的算法采用双阈值对不均匀光照的区域进行二值化处理,减少了伪影现象。该算法是全局阈值算法和局部阈值算法的结合,同时兼顾了处理效果和时间复杂度。
3.2 条码的区域定位
条码的区域定位计算较为复杂,因此算法的选择需要兼顾处理速度和处理效果。本文采用了基于连通域的区域定位算法[2],算法包括条码方向提取、条码区域连接和连通域标记3个步骤。图4给出了区域定位算法框图。
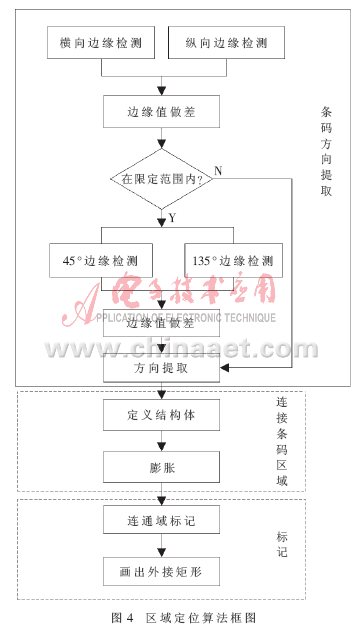
条码方向的提取决定了膨胀运算所使用的结构体。由于对图像直接进行膨胀运算很容易受噪声的影响,算法首先将图像区域分为水平、垂直、45°和135° 4种大致方向,而后提取条码的方向并根据条码不同的方向使用4种不同的膨胀结构体。这样有效防止了与条码接近的其他文字等背景由于使用各向同性的结构体进行膨胀运算而连接到条码中。方向提取先得到图像横向和纵向的梯度信息,而后以适当的阈值对得到的梯度图二值化并进行比较。认为含有较多边界信息的图指示的方向为条码的走向。如果两图边界的差值在一定范围内,则用同样的方法检测45°和135°两个方向。
膨胀算法将条码连成一个紧密的连通区域,之后要进行连通域的标记以定位条码区域。算法包含3个步骤:
(1)如果当前点A是前景点并且其前一点未被标记,则认为A是一个连通域的外轮廓点;跟踪这个外轮廓,并将所有外轮廓点都标记为与A属于相同的连通域。
(2)如果当前点A下方的点是背景点且A的前一点已被标记,则认为A是连通域内轮廓点;跟踪这个内轮廓,并将所有内轮廓点都标记为与A属于相同的连通域。
(3)如果前景点A的前一点已被标记且不属于情况1和2,则将A标记为与其前一点属于相同的连通域。
边界的跟踪是通过搜索像素点8临域实现的,用顺时针排布的1~7分别代表8临域点,搜索方向更新公式为:

系统采用的连通域标记法舍弃了传统的二次标记方式,而采用跟踪连通域外轮廓的方法,只需要对图像进行扫描,因此具有更快的速度。
3.3 条码的定位
本文提出时间复杂度较低的边缘跟踪算法,定位了条码的4个顶点,为条码倾斜和几何形变的校正提供条件。图5给出了定位算法流程图。
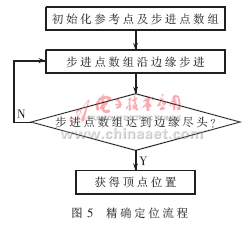
以搜索左上角顶点为例。系统用参考点数组记录搜索到的条码起始符或结束符的边缘走向,步进点数组沿起始结束符黑色边界方向逐点步进。若步进过程中某一时刻,步进点数组与参考点数组夹角超过45°,说明步进点数组已步进到条码边缘,则将步进点数组中心点位置确定为条码的左上顶点。用类似的方法搜索,可得到条码的其他3个顶点。
条码的4个顶点确定以后,再经过旋转变换、错切变换和透视变换,将几何形变的不规则四边形条码校正为矩形条码。条码的旋转使终端的解码不再局限于水平和垂直的条码,实现了PDF417的全方位解码。
3.4 条码分层及码字读取
PDF417是堆叠式条形码,需要确定条码的层次以进行逐行码字的读取。确定条码层次的步骤如下:
(1)用Sobel边缘检测算子作用于图像,提取图像边界。
(2)将得到的分层界限进行水平投影,记录投影点数目p(i)。
(3)隔行差分。按照dif(i)=p(i)-p(i-2)计算第i行的投影差分值。若当前行投影差分值大于零,而其下一行差分值小于零,则认为该行为分层界限。
(4)伪边界去除。将投影高度小于投影峰值1/4的边界去除,以消除由噪声产生的伪边界。
得到条码的层边界后,系统采用层内投影并判断投影高度的方法来读取每层条码的条空信息。实践证明该方法具有较高的正确率。
用条空的宽度除以单位模块的宽度得到条码的条空宽度序列,如:81111113…31111334…711311121.单位模块宽度求解方法为:

其中,Wm为单位模块宽度,Wl为层宽,n为一层条空总数。
终译码采用查表的方式将条空序列转换为码字序列。码字序列经过检错与纠错后,按照3种压缩模式编码的反方向进行译码,终得到PDF417条码的原始数据。
4 实验结果
对采集到的28 000幅、分辨率为320×480的图像进行测试。测试结果表明,本终端对PDF417条码的识别率可达99.76%,识别码解码正确率为100%,解码速度达10次/s以上,具有国内的技术水平。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。