摘 要: 本文提出了一种基于数据仓库的联机分析处理系统的解决方案,重点介绍了数据仓库的设计方法和联机分析处理方法。
我军总装备部提出“基于数据仓库的装备采购联机分析系统研究与设计”,将着力构建开放、规范、有序的装备采购市场,积极培育多元化的竞争主体,广泛吸引包括民营企业在内的各类所有制企业参与武器装备的预先研究、型号研制、购置、维修各阶段竞争,以进一步加快军队装备现代化建设步伐。装备采购联机分析处理系统作为决策支持系统的一部分,提供了一个多维的联机分析统计环境,具有分析预测形象、直观、效果好的优点。
1 数据仓库和联机分析处理技术
随着数据库技术的发展和应用,数据库存储的数据量从20世纪80年代的兆(M)字节及千兆(G)字节过渡到现在的兆兆(T)字节和千兆兆(P)字节,同时,用户的查询需求也越来越复杂,涉及的已不仅是查询或操纵一张关系表中的一条或几条记录,而且要对多张表中千万条记录的数据进行数据分析和信息综合,关系数据库系统已不能全部满足这一要求。在国外,不少软件厂商采取了发展其前端产品来弥补关系数据库管理系统支持的不足,力图统一分散的公共应用逻辑,在短时间内响应非数据处理人员的复杂查询要求
传统的数据库主要用于事务处理,通常对一个或一组数据完成增加、删除、修改、查询和一些基本统计操作,主要用于支持特定的应用服务,也称为操作型处理,侧重于响应时间、数据的安全性、一致性和完整性等方面。尽管在联机事务处理(On-Line Transaction Processing,OLTP)方面的应用获得了巨大的成功,随着社会的进步和技术的发展,人们不再仅仅满足于获取多种信息和简单的使用信息,而是希望在深层次上利用长期积累的历史信息为企业的决策提供帮助。
20世纪90年代初,W.H.Inmon在其着作《Building the Data Warehouse》中提出了数据仓库的概念。他认为数据仓库是面向主题的、集成的、稳定的、随时间变化的数据集合,用来支持管理决策。数据仓库中包含大量数据,这些数据可能来自企业或组织内部,也可能来自外部。这些数据组织为数据仓库的目的是为了能够更好地支持决策。目前,数据仓库在银行、股票、保险、电信、航空、医疗保健、零售及制造等领域都有应用。
联机分析处理(On-Line Analytical Processing,OLAP)是专门为特殊的数据存取和分析而设计的技术。它能够实现数据仓库基础上的多维数据分析。通过创建用于分析的多维数据集,进一步采用切片、切块、下钻、上翻及旋转等多维分析操作,帮助用户发现不同侧面、不同层次上的有用信息,从而使用户更加直观地理解和分析数据。
联机分析处理在内的诸多应用牵引驱动了数据仓库技术的出现和发展;而数据仓库技术反过来又促进了OLAP技术的发展。用户的决策分析需要对关系数据库进行大量计算才能得到结果,而查询的结果并不能满足决策者提出的需求。因此,Codd提出了多维数据库和多维分析的概念,即OLAP。OLAP委员会对联机分析处理的定义为:使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业维特性的信息进行快速、一致、交互地存取,从而获得对数据的更深入了解的一类软件技术。
目前,许多数据库厂商都推出了自己的数据仓库产品。本文采用的是Informix公司的Red Brick,它是为数据仓库和联机分析处理应用程序设计的关系数据库管理系统。该产品能够快速地装入和检索数据,特别是它的自动聚集对前台应用程序的开发是全透明的,极大地提高了常规分析的响应时间。Metacube具有如下的技术特点:(1)易扩展性。Metacube的元数据及计算中间表结构简单清晰,方便数据仓库的扩展;(2)开放性。Metacube在数据仓库的各个部分都是开放的,包括RDBMS服务器、客户端应用开发工具、随机查询工具和报表生成工具。另外,用户可以用自己喜欢的开发环境或前端应用作为数据仓库的前端平台;(3)具有强有力的查询优化功能,可以限度地提高效率。
2 系统设计
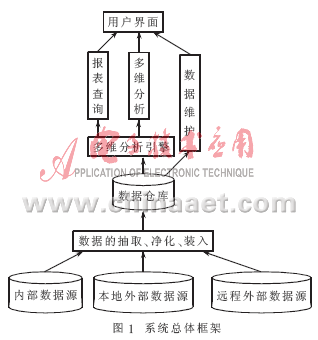
2.1 系统的总体框架
数据仓库为联机分析处理和决策支持提供了有效的数据存储和处理环境。通过对事务数据库的数据和外部数据的抽取、净化和转换,形成面向全局的数据视图,同时也解决了数据不统一的问题。前端的联机分析(OLAP)工具对这些数据进行分析处理。基于数据仓库的装备采购联机分析处理系统的总体框架如图1所示。
2.2 数据仓库设计
下面介绍数据仓库设计的步骤。
(1)确定用户需求。我军的装备采购业务系统积累了大量的历史数据,这些数据主要包括采购时间、装备名称、生产厂家、用途、采购经费、采购数量、采购价格等。如何对其进行分析研究,从而得出内在规律是一个相当重要的问题。为此,本文确定了装备购置费研究、装备采购量研究、装备采购价格研究和生产厂家分布规律研究等主题。
(2)逻辑设计。数据模型是数据仓库的问题之一。传统的数据模型(如实体模型和关系模型)不能有效地表示数据仓库中的数据结构和语义,也难以支持OLAP应用。量度可分为存储量度和计算量度:存储量度在数据仓库表中有实际的字段存放数据;而计算量度在数据仓库中没有相应的字段,而是在SQL查询语句中通过聚集函数获得。
本文设计多维数据模型的主要步骤是:①确定事实表和维度表;②设计事实表;③设计维度表。
多维数据模型有二种基本的结构:星型结构和雪花结构。图2所示为本系统数据仓库的雪花模型。

(3)物理设计。在确定了雪花模型后,需要将逻辑模型变成物理模型。物理模型建立数据仓库存储与备份、分段、检索、聚集策略等。由于数据仓库中存放着大量甚至海量的数据,为适应对这些数据处理的要求,现将性能优化的一些关键技术做简要的介绍:
索引:索引主要用于优化查询性能,对于数据装入的参照完整性检查阶段也相当重要。Red Brick包括B型树索引、TARGETindex和STARindex三种不同类型的索引。在Red Brick Decision Server数据库中生成表格时(基础表和临时表),如果表格定义了关键字,则关键字自动生成B树索引。TARGETindex是Red Brick Decision Server中的位图或位向量索引。这些类型的索引有二种用途:弱选择性维度列和事实表中的TARGETjion处理。STARindex是建立在事实表的外部关键字之上的惟一多列索引结构。
对于事实表来说,应该为它的所有外键建立TARGETindex,并要建立至少包含所有外键的STARindex。如果一个TARGETindex包含惟一标识每个事实行所需的列,则可以删除主关键字索引。如果不删除,则应使其尽量小。
对于维表来说,不要删除主关键字的B树索引。对每个外部关键字列生成B树索引对维度中作为悬臂表外部关键字的列应当检查,对查询中经常限制的列生成TARGETindex与树索引。
分段:分段是个数据管理工具,合理的分段有助于查询性能的改进。数据库越大,分段提供的好处就越大。段的类型有二种,即默认段和命名段,二者各有不同的功能。可以按连接某个事实表的任意维度的主关键字将数据仓库分段,大多数仓库按某种时间定义分段,例如日、周、月、季、年等。
聚集:决策支持查询中常见的操作之一是计算聚集汇总,如果没有聚集,则这些查询需要读取成千上万行数据才能计算和组合结果,查询运行时,将需较长时间等待结果。对聚集表运行查询具有更高效率。Red Brick Decision Server用独特的方法处理聚集:Vista子系统自动、透明地改写包含聚集函数的查询,提供另一类索引,在决策支持环境中提高偶发查询性能。
2.3 数据的抽取、净化、装入
数据的抽取、净化、装入的过程如下:
(1)从业务数据中抽取数据。增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据。在ETL使用过程中。增量抽取较全量抽取应用更广。如何捕获变化的数据是增量抽取的关键。对捕获方法一般有两点要求:准确性,能够将业务系统中的变化数据按一定的频率准确地捕获到;性能,不能对业务系统造成太大的压力,影响现有业务。
(2)净化数据。数据净化主要考虑以下三个方面:①确保所有值准确有效;②所有列中都具有有意义的值,没有缺失值;③每一行都保持参照完整性。
(3)装入数据。Red Brick Decision Server数据库从外部装入数据,应首先装入维表,然后再装入事实表。它提供的TMU实用程序能够快速地装入数据,具有良好的性能。TMU由指定输入与输出操作的控制脚本驱动。通过命令行调用TMU时,控制脚本作为命令行参数提供,TMU读取这个脚本,然后完成必要的工作。
例如:执行命令
rb_tmu -d <db_name> <control_filename> <username>
<password>
控制文件 Example.TMU 格式为:
load data
inputfile ′/apps/redbrick/sample_input/aroma_class.txt′
replace
format separated by ′!′
discardfile′/classn/stunnn/class.discards′
discards 10
into table class (
classkey integer external(2),classkey integer external,
class_type char(12),type character,
class_desc char(60) description character)……);
其中aroma_class.txt为之前抽取的数据文件。
Red Brick Decision Server的装入器有二个版本:串行(TMU)和并行(PTMU)。并行装入器主要用于多个CPU的装入和联机装入,并行装入比串行装入速度快。
2.4 多维联机分析设计
多维数据的联机分析处理就是从不同的角度和层次查询满足分析需求的数据。OLAP分析的基本操作动作有:切片、切块、旋转和钻取。如图3所示为“时间、装备、厂家”的三维立方体,可以在上面完成上述操作。

联机分析处理的主要特点,是直接仿照用户的多角度思考模式,预先为用户组建多维的数据模型,在这里,维指的是用户的分析角度。例如对销售数据的分析,时间周期是一个维度,产品类别、分销渠道、地理分布、客户群类也分别是一个维度。一旦多维数据模型建立完成,用户可以快速地从各个分析角度获取数据,也能动态的在各个角度之间切换或者进行多角度综合分析,具有极大的分析灵活性。这也是联机分析处理在近年来被广泛关注的根本原因,它从设计理念和真正实现上都与旧有的管理信息系统有着本质的区别。
(1)切片。切片就是在多维模型的某一维上选定一维成员。例如在厂家维上选择一个维成员(设为“厂家1”),就得到了厂家维上的一个切片。这个切片表示厂家1每年生产各种装备的情况。
(2)切块。切块可以看成是在切片的基础上,进一步确定各个维成员的区间得到的片段体,即由多个切片叠合起来。例如在时间维上设定一个区间(例如取“1990年至2000年”)。
(3)旋转。旋转是改变维度的位置关系,使终用户可以从多角度来观察数据。如将横向的时间维和厂家维进行交换,从而形成横向为部门、纵向为时间的报表。
(4)钻取。如果维度是有层次的,则可以采取钻取,包括向上钻取(roll up)和向下钻取(drill down)。roll up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;而drill down则相反,它从汇总数据深入到细节数据进行观察 。例如装备维上可以从装备大类向装备中类钻取,装备中类再向装备小类钻取。
用户可以在Metacube Explorer中指定显示哪一维,可以在任意坐标轴上查看不同维、不同层次的信息或者数据仓库上的其他有关信息。它所生成的报表和统计图形象直观,便于用户进行对比、分析。其开放性可以使开发人员利用前端工具进行开发,以满足具体的要求。
3 系统开发
该系统采用C/S模式,服务器操作系统是Windows 2000 Server,客户端操作系统采用Windows 98、Windows 2000 Professional或Windows XP,中心数据仓库产品采用Informix Red Brick,OLAP分析工具为Informix Metacube,前端应用程序采用Visual Basic 6.0开发。
4 结束语
该系统是数据仓库技术在装备采购业务中的一个有益尝试,使原有的分析工作更加方便高效、形象直观。作为装备采购决策支持的一部分,该系统还需要进一步的设计和完善,在现有数据仓库的基础上,开发数据挖掘模块。随着系统的逐步完善,必将能够为我军装备采购决策人员提供科学的依据,从而推动我军装备采购决策现代化的进程,用更先进的武器为解放军服务。能更好的保卫我国的边疆。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。