HD 6000系列显卡是AMD(ATI)历史上首先采用数字式PWM供电设计的图形产品,其控制器由CHiL公司提供,为CHL系列。AMD Radeon HD 6800系列显卡的发布, 揭开了AMD新一代显卡Radeon HD6000系列问世的序幕。在AMD的推动下,GPU显示技术又将跃升至一个更高的层次。
● HD6000架构效率摸底
AMD推出的支持DirectX11的HD5000系列显卡,RV800架构下的HD5000系列产品给用户带来了以前从未有过的新API体验,也给图形业界留下了一些思考。
首先是从HD2000以来坚持至今的VLIW组织形式SIMD结构流处理器还能沿用多久,其次是Tessellation功能的实现是否仅需要一个特殊功能单元,当然用户对这种架构的执行效率和提升空间也有不同观点。

AMD再次用较小的架构改动再次撬动了GPU关键性能的提升,HD6000发布之后我们看到了一颗面积更小的芯片融聚了更高的浮点运算能力,我们看到通过改善线程控制能力流处理器和特殊功能运作效率进一步提升,当然这一切的背后,还有AMD利用TSMC改进后的40nm CMP碱洗工艺提升整体频率带来的线性性能提升。
HD6000架构和工艺有何改进,这种改进下的效率真的能有提升吗?今天的分析和测试将为我们的用户提供一些线索和数据,让我们共同体会AMD在HD6000系列显卡设计中的过人之处和性能短板。
● 用代价占领甜蜜点市场
为了更好的体现AMD收购ATI后灵活多变的产品优势和图形架构简单易行的特性,AMD从HD2000开始不断完善款统一渲染架构GPU——Xenos处理器,这款GPU的特色是采用了统一着色器单元架构,顶点、像素着色器程序都在同样的单元上执行,由线程调度器作动态的资源分配,还引入了顶点纹理拾取(VTF单元)等ATI同期R5XX产品所不具备的特性。
AMD在R600时期首先放大规模,然后让这款GPU支持了当时主流的DirectX 10,在RV670时期主要攻占对手忽略的甜蜜点(100到200美元)价位段;在RV770时代则依靠工艺拉力将流处理器放大到800个;到了RV870时代在运算单元外围加入DirectX 11所需的特殊功能支持,并全面兼容Open CL作为通用计算平台。
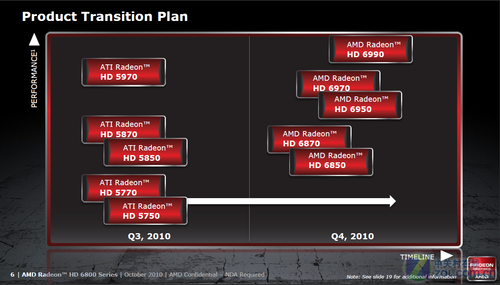
HD6800系列是甜蜜点战略
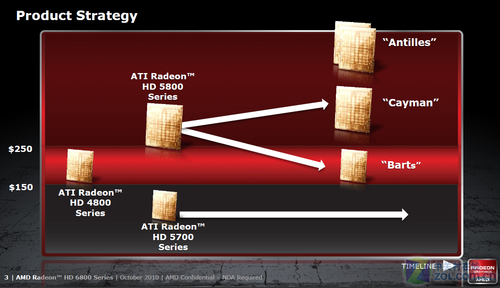
HD6800系列所使用的Barts定位
本次发布的HD6800系列显卡作为第二代DirectX 11架构设计,并没有像我们之前所预期的对RV870架构进行伤筋动骨的改进,而是通过提高固定单元频率和改进线程分配能力达到了更高的流处理器资源利用率。重要的是HD6800并非端单卡,它不代表HD6000系列的性能,但是它在1200-1800元人民币之间的市场定位使之成为甜蜜点战略的。

用于Radeon HD 6870的Barts


面积255mm2
Barts面积公布为255mm2,我们使用电子游标卡尺粗略测的为18.25mm*14.83mm,约等于255mm2。通过实物图不难发现,Barts并非正方形设计,而是长方形设计,这让笔者想起了其直接竞争对手GF104。
Barts的设计目标主要有以下几点:
1、在较低功耗和价格上对AMD Radeon HD 5800系列进行性能优化
2、提供当前性能/性能/平方毫米
3、功耗低于150瓦显卡市场当中性能产品
为达成以上目标,AMD在设计Barts时选择了以下几种方式:
1、设计一颗集成度不高于19亿的,和对手的GF104相仿
2、改进HD5000的线程分配能力和固定单元几何处理能力
3、必须严格控制功耗,依靠半导体工艺来提升性耗比
曾经有人用“满脑子充满肌肉”来形容R600-R800以来的架构设计,这句话的含义是芯片拥有强大的浮点吞吐能力而缺乏线程仲裁与管理能力。而反观对手NVIDIA虽然动用耗费了大量晶体管的GTX480才打赢了HD5870,但是为什么NVIDIA要花费如此庞大的晶体管固执地坚持TLP(线程并行度)设计思路?为什么NVIDIA要不断添加周边资源以提升线程仲裁能力甚至不惜放弃纯浮点吞吐?
缺乏线程仲裁与管理能力,这正是AMD所面临的架构设计困局,而这种困局在DirectX11时代由于新技术的加入被明显放大。所以AMD开始在HD6000时代寻求一些变化和突破,尽管它们看起来很不起眼,但是却成为未来AMD优化图形芯片架构的重要方向。
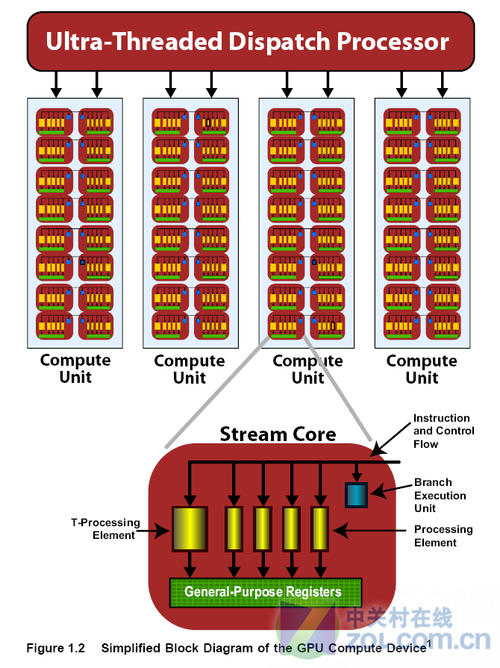
AMD图像处理器构成简图
从R600到R800时代,每个流处理单元都包含5路超标量体系结构着色处理器,单时钟周期可以多处理5个标量乘加指令,其中一路着色处理器负责处理超越指令(比如Sin、Cos、Log、Exp等等)。图中5个黄色的长方形就是5路着色处理器,其中较大的一个就是可以处理超越指令的着色处理器。流处理单元可以达成32-bit浮点,支持整数和逐位操作,图中紫色的长方形“分支执行单元”则负责进行流控制和条件运算。
而控制这些流处理器的,则是AMD在R520时代ATI开始引入Ultra Threaded Dispatch Processor单元,UTDP为不同的shader类型提供了专门的命令队列窗口,这些窗口内塞满了等待执行的线程,每个线程都是若干条对输入数据处理的指令。UTDP属于GPU前端逻辑。Ultra-Threaded Dispatch Processor,也被译为超级线程分配器,如字面意思,负责GPU全局线程分配,既然是“全局”,就应该一个GPU只有一个,但HD6000系列有两个,每个都只负责各自7组SIMD Core的线程分配。
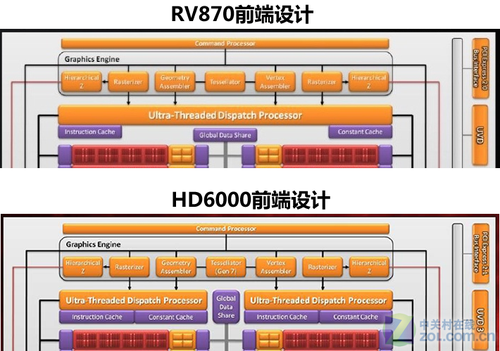
RV870与HD6000前端设计
本次Barts在架构上的变化主要有三点:
1、Tessellator数量仍为1组,但是为增强型的Tessllator Gen7。
2、线程控制器由Cypress的一组变为Barts现在的两组。
3、UVD引擎升级至第三代,提供了更多功能及格式的图形计算模式。
● 40nm碱洗工艺换取固定单元频率
本次HD6800系列Barts的另一个重要特点就是额定运行频率较高,其900MHz频率在以前的GPU中从未出现过。AMD之所以能够在这颗中采取高频策略的重要原因,主要原因是使用了TSMC提供的40nm CMP碱洗工艺。。

CMP是Chemical Mechanical Polishing (化学机械研磨)的英文缩写,是IBM在上世纪八十年代发明的一项技术。当今电子元器件的集成度越来越高,要使这些晶体管能够正常工作,就需要对每一个晶体管加一定的电压或电流,这就需要引线来将如此多的晶体管连接起来,但是将这幺多的晶体管连接起来,平面布线是不可能的,只能够立体布线或者多层布线。在制造这些连线的过程中,层与层之间会变得不平以至不能多层迭加。用CMP来实现平坦化,使多层布线成为了可能。

不同酸碱度PH值溶剂清洗半导
上图就是不同酸碱度PH值溶剂清洗半导体时产生的效果,浅色区域就是铜导线,上面的斑痕就是残留的二氧化硅。DW代表原始未清洗,表面直接附着了一层二氧化硅。不完全洗掉电磁环境就很乱,洗不好就导致半导体芯片不能运行在高频。但是如果洗的太彻底,二氧化硅基体被洗穿就会造成直接短路。

过度残留与过度腐蚀
第二张图片是TSMC提供的某个实验电路,左图表示CMP酸洗工艺,中我们可以看到放大的导线表面残留二氧化硅的SEM,而右图中的碱洗工艺下很明显二氧化硅基底被过度腐蚀,导线发生短路。
目前TSMC现在正在调整PH值,试图通过控制酸碱度,争取牺牲一部分二氧化硅残留率来换取良率,只要降低PH值基体就会趋近稳定。但是这样做的代价就是表面二氧化硅残留率,不的来折算,代价就是极限频率,所以提高良率,会导致芯片极限频率会降低。而过分重视高频,则芯片会出现大面积良率降低。

HD6870相对与HD5850的性能提升
如果不考虑运行频率,HD5850和HD6870的区别只在于SIMD Core组数,也就是流处理器数量,两款芯片的固定单元数量是基本相等的(HD6800纹理单元有减少,UTDP单元翻倍)。但是当HD6870披上高频外衣之后,其线程分配能力、几何吞吐能力、光栅化与Z轴处理能力都获得了线性提升。
所以AMD本次首先精简流处理器数量,尽力缩小芯片集成度和面积,在此基础上加之TSMC 40nm CMP碱洗工艺做支撑,将HD6800系列运行频率提升到前所未有的高度,使线程分配能力和几何处理能力依靠高频的固定单元获得重要提升,进一步减弱了RV870架构的设计短板。
● 测试系统硬件环境
| 测 试 平 台 硬 件 | |
| 中央处理器 | Intel Core i7-870 OC3.5GHz |
| 散热器 | Thermalright Ultra-120 eXtreme |
| 内存模组 | Apacer 猎豹二代双通道套装/PC3-12800 |
| (SPD:1757 9-9-9-24-1T) | |
| 主板 | ASUS P7P55D |
| (Intel P55 + ICH10R Chipset) | |
| 显示卡 | |
| AMD 产 品 | |
| Radeon HD 6870 | |
| (Barts / 1024MB / :900MHz / Shader:900Mhz / 显存:4200 Mhz) | |
| Radeon HD 5850 | |
| (Cypress / 1024MB / :725MHz / Shader:725Mhz / 显存:4000 Mhz) | |
| NVIDIA 产 品 | |
| GeForce GTX 460 1024MB | |
| (GF104 / 768MB / :675MHz / Shader:1350Mhz / 显存:3600 Mhz) | |
| 硬盘 | Hitachi 1T |
| (1TB / 7200RPM / 16M | |
| 电源供应器 | AcBel R8 ATX-700CA-AB8FB |
| (ATX12V 2.0 / 700W) | |
| 显示器 | DELL UltraSharp U2410 |
| (24英寸LCD / 1920*1200分辨率) | |




● 测试系统的软件环境
| 操 作 系 统 及 驱 动 | |
| 操作系统 | |
| Microsoft Windows 7 Ultimate RTM | |
| (中文版 / 版本号7600) | |
| 主板芯片组 驱动 |
Intel Chipset Device Software for Win7 |
| (WHQL / 版本号 9.1.1.1125) | |
| 显卡驱动 | |
| AMD Catalyst for Win7 | |
| (WHQL / 版本号 10.10) | |
| NVIDIA Forceware for Win7 | |
| (WHQL / 版本号 258.96) | |
|
|
2560*1600_32bit 60Hz |
| 测 试 平 台 软 件 | |
| 3D合成 测试软件 | |
| 3Dmark Vantage | |
| Futuremark / 版本号1.2 | |
| DirectX 11 理论测试项目 |
DirectX 11 SDK Nbody Gravity |
| Microsoft / 版本号 Demo | |
| HDRToneMapping CS11 | |
| Microsoft / 版本号 Demo | |
| DX11 SDK Test:Sub D11 | |
| Microsoft / 版本号 Demo | |
| 辅助测试软件 | Fraps |
| beepa / 版本号 3.2.3 | |
各类合成测试软件和直接测速软件都用得分来衡量性能,数值越高越好,以时间计算的几款测试软件则是用时越少越好。
3DmarkVantage是Futuremark推出的一款显卡3D性能测试,该款软件仅支持DirectX 10系统及DirectX 10显卡。测试成绩主要由两个显卡测试和两个CPU测试构成,整个测试软件各家偏重整机性能。







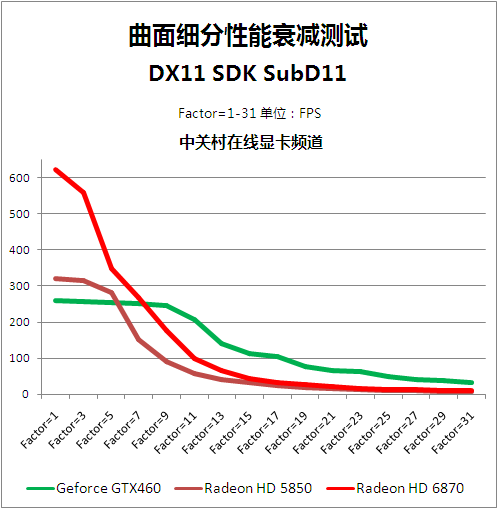
● SubD11曲面细分性能衰减
Direct X11 SDK Test:Sub D11是集成在微软的DirectX SDK开发包中的测试组件之一,它主要测试GPU的Tessellation性能。这个测试一共包含31个层级,从级的轻度曲面细分到31级重度曲目细分,对显卡的几何处理能力考验不断升级。




● DirectX 11 SDK Nbody Gravity
DirectX 11 SDK Nbody Gravity项目源于Nbody仿真,它在数值上近似地表示一个多体系统的演化过程,该系统中的一个体(Body)都持续地与所有其他的体相互作用。一个相似的例子是天体物理学仿真,在该仿真中,每个体代表一个星系或者一个独立运行的星系,各个体之间通过万有引力相互吸引,如图所示。
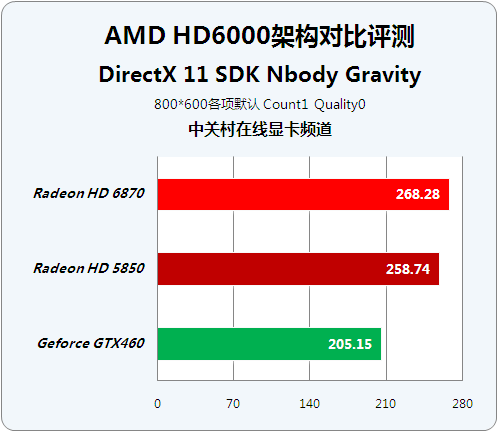
● HDRToneMapping CS11
HDRToneMapping CS11测试项目同样是针对Computer Shader能力进行测试,该项目展示了如何设置和运行计算着色器(Computer Shader),这是令人兴奋的Direct3D 11的新功能之一。虽然该测试只是检验了这项技术在HDR(High-Dynamic Range)高动态光照渲染中的加速能力,但是这个概念应该很容易扩展到其他后处理算法,以及更一般的计算。
这项测试我们选择了DirectX 11所推荐的Computer Shader渲染模式,在测试中NVIDIA显卡出现了负载不饱和状态,所以整体得分不理想。联系到NVIDIA在Fermi架构中对并行计算的支持和多级多分配多线程能力,这个得分还是比较让人失望的,我们只能希望NVIDIA通过新驱动开发继续优化带有缓存的Fermi架构。

测试总结:
作为AMD延续并改进HD5000架构的中高端产品,HD6800系列显卡凭借细微的架构改动。在AMD提出的自适应曲面细分新思路下,Tessellation性能表现发生了一些变化。但是Computer Shader性能则依然依靠流处理器规模和线程控制器改进来实现,这部分性能毫无疑问提升缓慢。
从HD5000和Fermi架构开始,可看到NVIDIA、AMD对DX11的不同理解产生了两种接近极端的做法。AMD几乎不用添加大量晶体管即可完成微软的DirectX 11要求,固定功能单元如Tessellator(曲面细分单元)的添加都是在执行单元外围;而NVIDIA则把问题考虑的太过于复杂,它显然看到了Computer Shader技术的巨大前景,同时每一个DX11特性都要达到才善罢甘休,因此对晶体管开销有一定程度依赖。
现在来看通过降低并行度提升线程管理能力来缩小芯片面积,同时依赖近的半导体工艺制程来提高固定单元频率,对AMD而言的确是一条为便捷的道路。不过我们还是希望在未来看到AMD的更多改变,毕竟一味放大流处理器规模可能会让芯片前后端成为性能瓶颈,同时越来越多的图形应用正在结合Computer Shader技术向普通用户蔓延,解决好架构效率问题将成为GPU厂商永恒思考的问题。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。