摘要:相对解码重建后的语音进行说话人识别,从VoIP的语音流中直接提取语音特征参数进行说话人识别方法具有便于实现的优点,针对G.729 编码域数据,研究基于DTW算法的快速说话人识别方法。 实验结果表明I在相关的说话人识别中,DTW算法相比GMM在识别正确率和效率上有了很大提高。
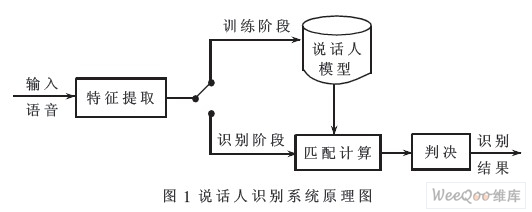
说话人识别又被称为话者识别,是指通过对说话人语音信号的分析处理,自动确认说话人是否在所记录的话者集合中,以及进一步确认说话人的身份。说话人识别的基本原理如图1所示。
按照语音的内容,说话人识别可以分为文本无关的(Text-Independent)和文本相关的(Text-Dependent)两种。文本无关的识别系统不规定说话人的发音内容,模型建立相对困难,但用户使用方便。与文本有关的说话人识别系统要求用户按照规定的内容发音,而识别时也必须按规定的内容发音,因此可以达到较好的识别效果。
随着网络技术的发展,通过Internet网络传递语音的*VoIP(Voice over IP)技术发展迅速,已经成为人们日常交流的重要手段,越来越多的用户抛弃传统的通信方式,通过计算机网络等媒介进行语音交流。由于VoIP工作方式的特点,语音在传输中经过了语音编译码处理,VoIP设备端口同时要处理多路、海量的压缩话音数据。所以VoIP说话人识别技术主要研究的是如何高速、低复杂度地针对解码参数和压缩码流进行说话人识别。
现有的针对编码域说话人识别方法的研究主要集中在编码域语音特征参数的提取上,香港理工大学研究从G.729和G.723编码比特流以及残差中提取信息,并采用了分数补偿的方法。中国科学技术大学主要研究了针对AMR语音编码的说话人识别。西北工业大学在说话人确认中针对不同的语音编码差异进行了补偿算法研究,并且研究了直接在G.729编码的比特流中提取参数的方法。说话人模型则主要采用在传统说话人识别中应用广泛的GMM-UBM(Gaussian Mixture Model-Universal Background Model)。GMM-UBM的应用效果和混元数目密切相关,在保证识别率的基础上,其处理速度无法满足VoIP环境下高速说话人识别的需求。
本文研究VoIP语音流中G.729编码域的说话人实时识别,将DTW识别算法成功应用在G.729编码域的文本相关的说话人实时识别。
1 G.729编码比特流中的特征提取
1.1 G.729编码原理
ITU-T在1996年3月公布G.729编码,其编码速率为8 kb/s,采用了对结构代数码激励线性预测技术(CS-ACELP),编码结果可以在8 kb/s的码率下得到合成音质不低于32 kb/s ADPCM的水平。 G.729的算法延时为15 ms。由于G.729编解码器具有很高的语音质量和很低的延时,被广泛地应用在数据通信的各个领域,如VoIP和H.323网上多媒体通信系统等。
G.729的编码过程如下:输入8 kHz采样的数字语音信号先经过高通滤波预处理,每10 ms帧作线性预测分析,计算10阶线性预测滤波器系数,然后把这些系数转换为线谱对(LSP)参数,采用两级矢量量化技术进行量化。自适应码本搜索时,以原始语音与合成语音的误差知觉加权为测度进行搜索。固定码本采用代数码本机构。激励参数(自适应码本和固定码本参数)每个子帧(5 ms,40个样点)确定。
1.2 特征参数提取
直接从G.729 编码流中按照量化算法解量化可以得到LSP参数。由于后段的说话人识别系统还需要激励参数,而在激励参数的计算过程中经过了LSP的插值平滑,所以为了使特征矢量中声道和激励参数能准确地对应起来,要对解量化的LSP参数采用插值平滑。


本文选择G.729编码帧中子帧的LSP(1)参数的反余弦LSF及由其转换得到的LPC、LPCC参数作为声道特征参数。
参考文献[1]发现识别特征加入G.729压缩帧中的语音增益参数,说话人识别性能发生了下降。去除G.729压缩码流特征中的增益参数GA1、GB1、GA2、GB2,结果发现,当采用了去除增益参数的特征矢量方案X=(L0,L1,L2,L3,P1,P0,P2),识别性能得到了提高,所以本文终采用的G.729压缩码流特征为X=(L0,L1,L2,L3,P1,P0,P2),共7维。
2 动态时间规整(DTW)识别算法
动态时间规整DTW(Dynamic Time Warping)是把时间规整和距离测度计算结合起来的一种非线性规整技术。该算法基于动态规划思想,解决了发音长短不一的模版匹配问题。
算法原理:假设测试语音和参考语音分别用R和T表示,为了比较它们之间的相似度,可以计算它们之间的距离D[T,R],距离越小则相似度越高。具体实现中,先对语音进行预处理,再把R和T按相同时间间隔划分成帧系列:
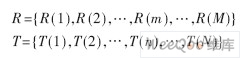
然后采用动态规划进行识别。如图2所示。
把测试模版的各个帧号n=1,…,N在一个二维直角坐标系的横轴上标出,把参考模版的各帧号m=1,…,M在纵轴上标出,通过这些表示帧号的整数坐标画出的横纵线即可形成一个网格,网格中的每一个交叉点(n,m)表示测试模版中某一帧与训练模版中某一帧的交叉点。动态规划算法可以归结为寻找一条通过此网格中若干格点的路径,路径通过的格点即为测试和参考模版中距离计算的帧号。

整个算法主要归结为计算测试帧和参考帧间的相似度及所选路径的矢量距离累加。
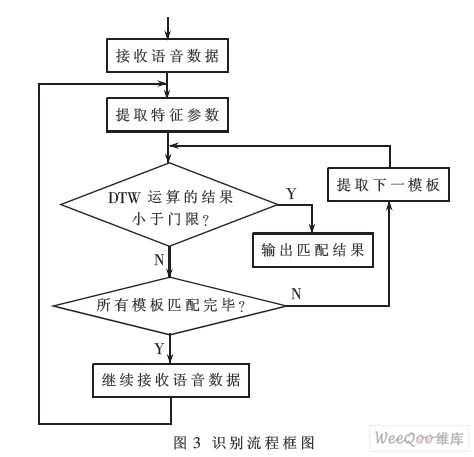
识别流程如图3所示。
3 实验结果与性能分析及结论
为测试上述识别性能,对其进行了固定文本的说话人识别试验。试验中,采用电话信道863语料库30个说话人共300个录音文件,文件格式为16 bit线性PCM。为了模拟VoIP中语音压缩帧,使用G.729声码器对原始语音文件进行压缩。使用每个说话人的一个文件训练成为模板。测试语音长度为10 s~60 s以5 s为间隔的共11个测试时间标准。这样,模板库中有30个模板,测试语音有270个,使用微机配置是:CPU Pentium 2.0 GHz,内存512 MB。
在实验中,M和N取64,通过各模版间的匹配,确定了判决门限为0.3时,识别效果。
为了对比DTW算法的识别性能,采用在传统说话人识别中广泛使用的GMM模型作为对比实验,其中GMM模型使用与DTW算法相同的编码流特征。
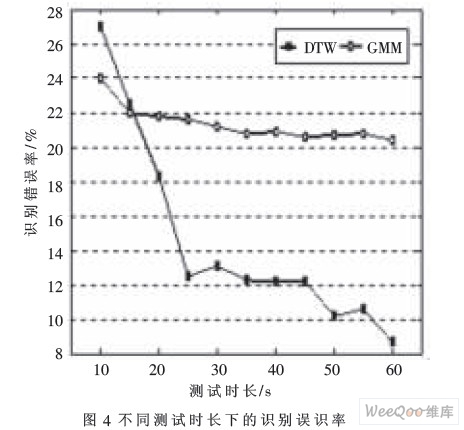
图4给出基于DTW识别方法与GMM模型(混元数64)识别G.729编码方案863语料库的文本相关说话人的误识率对比图。横坐标代表的测试语音的时长,纵坐标代表识别误识率。由实验结果可知在文本相关的说话人识别中,基于DTW算法的识别率在绝大多数情况下高于GMM模型,且随着测试语音的增长,优势更明显。
为比较特征提取的时间性能和总的时间性能,实验条件如下:
(1)选择的50个说话人的语音只进行特征提取,测试语音长度总和在25 min左右;
(2)对测试语音分别进行解码识别和编码流的识别,模板数为10个;
(3)微机配置为:CPU Pentium 2.0 GHz,内存512 MB。
表1为特征提取时间比较结果,表2为说话人识别时间比较结果。
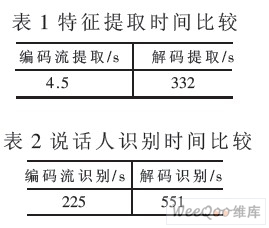
由实验结果可以看出,在编码比特流中进行特征提取时间和识别的(上接第121页)时间都远小于解码重建后的语音特征提取时间和识别时间,满足实时说话人识别的需要。
在文本相关的说话人识别中,对比使用同样G.729压缩码流特征的GMM模型, DTW方法的识别率和处理效率均高于GMM模型,能够实时应用于VoIP网络监管中。
[1]. G.729 datasheet https://www.dzsc.com/datasheet/G.729+_2060769.html.
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。