摘要: 本文基于目前SOC系统技术的发展情况,设计一个可用于SOC系统的核,该核的指令集完全兼容于MCS-51系列的微控制器。本设计的目的在于提高MCS-51的指令执行速度的同时兼顾面积的考虑,提升其在Soc系统中的应用价值。该IPCORE采用数据总线和指令总线相分离的哈佛总线结构和全新的指令时序以及指令实现方式,并使用PLA硬布线逻辑代替微程序控制,加快了核的速度,提高了指令执行效率。所有的模块都采用vhdl硬件描述语言进行设计描述,使用EDA工具进行功能仿真、综合。
1 前言
当前,在微电子及其应用领域正在发生一场前所未有的变革,这场变革是由片上系统(SOC)技术研究应用和发展引起的.从技术层面看SOC技术是超大规模集成电路发展的必然趋势和主流,它以超深亚微米VDSM(Very Deep Submicon)工艺和知识产权IP核复用技术为支撑。在众多的IP核中,MCU CORE以其在SOC中嵌入后能充分发挥其处理灵活、软件可升级、硬件开销少的特点,在很大程度上成为SOC芯片必需模块。INTEL公司的MCS-51系列MCU 可以说是目前国内应用时间长、普及、可获得应用资料多的功能强大的8位MCU , 所以建立兼容51指令MCU可综合IP核对于各种嵌入式系统和片上系统(SOC)的应用具有重要意义。
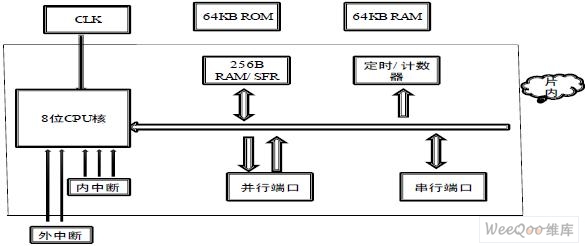
图1 IPCORE 内部结构
2 总体构架设计
本设计采用自顶向下的设计方法成功设计了与MCS-51 系列微处理器指令集完全兼容的8位嵌入式MCU核, 此核的内部结构如图1所示(整个设计过程也是围绕其产开)。
3 核内单元(主要单元设计的概述)
3.1 ALU 单元的设计:
ALU单元由一些基本操作功能模块(加/减法模块、乘法模块、除法模块、十进制调整模块和逻辑模块)构成,整个操作是通过多路选择器来完成的。在ALU单元的结构上,将乘、除法单元各自独立出来完成算术运算指令中的乘、除法运算。这样可以回避传统典型微处理器基于累加器ACC的ALU结构,并且由于ALU单元被设计成纯组合逻辑,因而速度较快,从而提高算术运算指令的执行效率。
3.2 时序设计
主要从简化控制器设计、提高核的性能出发,本设计没有采用Intel MCS-51双相时钟的复杂时序设计,而是采用单相时钟(单相时钟因为在时序和传输上比较简单可靠,被一些高性能芯片使用)、全同步设计,所有时序电路均采用边沿触发的触发器。采用单相时钟全同步设计会使芯片面积有所增加,但降低了设计的复杂度,减少了生产工艺不确定性对系统性能的影响,提高了设计的成功率。
3.3 控制单元的设计
控制器本质上是一个结构及状态转移非常复杂的有限状态机(FSM)。从程序执行的宏观角度看,每一条指令对应着这个复杂的有限状态机的一个状态,一条一条指令的依次执行,就是一系列状态转移。控制器的实现主要有两种:硬布线实现方式和微程序实现方式。考虑到本次设计的是一个用于SOC的IP核所以采用PLA技术,就是用存储技术实现硬布线逻辑,可以认为它是硬布线逻辑控制器和微程序控制器两者的折衷方案。由于PLA微控制器集中了硬布线逻辑控制器与微程序控制器两者的优点,与硬布线逻辑控制器相比,它的设计工作量小,修改、维护都比较方便。与微程序控制器相比,它的速度较快。这些优点都适合其作为内核整合在SOC中。为了提高FSM的效率,我们把控制单元中组合逻辑和时序逻辑分开设计,组合逻辑主要输出控制信号并且产生次态逻辑,时序逻辑主要实现存储单元的读写。
3.3.1 指令状态的设计

图2 指令状态机状态图
如图2 所示状态机共有五种状态,每个状态转换时间都对应一个时钟周期,所有指令共有状态为取指状态(取指令操作码)和开始状态(复位后的状态),中间的执行状态根据不同指令来分别采取1 到3 个执行步骤,比如ADD A RN 需要一个执行步骤,ADD A #DATA 需要两个执行步骤等。这样所有的指令就可以在一到四个时钟周期内完成整个指令的执行过程。
3.3.2 指令状态机的实现
51指令按功能分为五类:数据传送类;算术操作类;逻辑操作类;控制程序转移类;布尔变量操作类。出于减少内部连线和控制方便的考虑,我们将不同类的指令放在了不同的模块中解码执行。
算术操作类指令和逻辑操作类指令由指令译码控制模块实现译码,产生操作数和ALU控制命令,然后传送给算术逻辑运算单元ALU 完成运算,ALU 模块将运算结果送回指令译码控制模块,再由指令译码控制模块将结果写回目的单元。
数据传送类指令中的MOVX指令的实现需要所有外部控制时序信号的配合。在输出控制逻辑中直接产生MOVX所需的控制信号。数据的输入输出则在指令译码控制模块中实现。数据传送类中其他指令和布尔变量操作类指令中的非转移指令都直接在指令译码控制模块中实现,通过内部总线实现内部存储器、寄存器,外部存储器之间的数据传送。
控制程序转移类指令由于与程序计数器直接相关,因而这一类指令中的长调用指令、调用指令、长转移指令、转移指令、相对转移指令、子程序返回指令的PC计算放在了状态机时序部分PC计算模块,完成取指操作;而条件转移指令和布尔变量操作类中的测试转移指令则由指令译码控制模块完成测试比较操作,将比较结果送回PC计算模块使其根据比较结果来完成转移操作;由于数据传送类指令中的MOVC指令直接操作程序计数器,因而它的实现也放在了这个模块中。
4 核内其他单元的设计
4.1 中断单元的实现: 此次IPCORE 共有5 个中断包括两个外部中断,三个中断。中断源的检测是在状态机时序部分完成,执行中断程序之前操作如PC 装载中断向量值,PC 值的保存,清除中断标志等是在状态机的组合逻辑部分实现。
4.2 定时计数单元和UART 的设计:两个多功能16 位定时/ 计数器,我们用两个进程分别来实现。定时/ 计数器1 与定时/ 计数器0 类似,但它输出一个溢出脉冲到串行接口,给串行接口提供波特率。溢出中断标志输出到中断处理模块。串行口是一个全双工通信接口,它可作UART 用,也可以作同步移位寄存器用。我们用两个进程来分别实现其收发功能。收发所需时钟在进程外实现,模式1、2、3 的区别只是时钟和位数不同,故放在一起实现。
4.3 存储器设计:核内包含256B 的存储器,其中低128 单元作为用户RAM,高128 单元作为SFR.外部RAM 和ROM 可根据需要任意扩展到64KB。此次设计采用哈佛总线结构,ROM 和RAM 区由控制模块分别提供数据,地址传送总线以及控制信号线。内部RAM 和外部RAM 的读写也采用不同的控制线独立控制。这样的并行结构加速了指令执行的过程,有利于速度的提升。
5 功能和时序仿真的结果
5.1 功能测试
编完代码后,将所有模块整合,接下来就需要搭建测试平台(testbench),写激励文件,进行功能仿真。在源代码调试阶段,编写一简单的指令来进行仿真,然后看波形就可以了。当所有指令的调试基本通过的时候,就要对其进行全功能仿真,因此,针对此核的不同功能,如外中断、定时器/计数器、UART等需要编写不同的测试文件,以保证其在多种情况下都能正常工作。
测试平台见图

图3 测试平台的建立模式
利用Mentor Graphics 的工具MODELSIM SE/对模型进行了模拟验证。此处仅给出了一个简单的指令执行后的模拟结果(见图4)。图中所示为ADD A RN指令的波形图,可以看出,模拟结果与指令执行结果一致。该模型也通过了MODELSIM的可综合性检查。

图4 指令ADD A RN 执行结果
5.2 时序测试
在时序测试中我们选用了ALTERA 公司的不同系列FPGA 芯片来对次IPCORE 进行综合,综合后的性能如下表所示:

从上表我们可以看出虽然不同的器件综合后的结果不相同,但是本文设计的8 位MCUIPCORE 可以完全可以容纳到一个相对门数为20 万门以上的FPGA 中,并且具有较好的时钟频率特性。
6 结论
虽然这里只设计了一款八位的MCU IP CORE,但我们所提出的架构和模块设计新思路可以推广到16位、32位以及64位MCU的设计中。因为不管是多少位的MCU CORE,设计中需要重点考虑的架构以及指令系统基本上是一致的,所不同的只是一些总线位数以及寄存器的位数而已。当然随着位数的增加,一些验证和测试的复杂度也将显著增加,但从设计思路的角度来讲,它们是一样的。在具体的推广中,要根据应用领域的不同,对这些方法进行适当的取舍或适当的改进,以更加符合某些具体应用领域的要求。
本文创新点:本文设计了一种新结构的兼容51指令的MCU IPCORE。设计中引入了纯组合的ALU单元,增加了并行乘除法器,重新设计了外围组件,在设计控制单元的时候,重新设计了指令的时序,并且把指令状态机的时序和组合部分分开设计,提高了状态机的执行效率。从结果上看,时钟频率提高了很多,可由用户根据需要选择合适的ROM和RAM 的大小,并且完全可以把此核放在一个相对门数在20万门以上的FPGA的中。
免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。