 1 语音识别算法 目前,常以单片机(MCU)或DSP作炎硬件平台的实现消费类电子产品中的语音识别。这类语音识别主要为孤立词识别,它有两种实现方案:一种是基于隐含马尔科夫统计模型(HMM)框架的非特定人识别;另一种是基于动态规划(DP)原理的特定人识别。它们在应用上各有优缺点。HMM非特定人员的优点是用户无需经过训练,可以直接使用;并且具良好的稳定性(即对使用者而言,语音识别性能不会随着时间的延长而降低)。但非特定人语音识别也有其很难克服的缺陷。首先,使用该方法需要预先采集大量的语料库,以便训练出相应的识别模型,这就大大提高了应用此技术的前期成本;其次,非特定人语音识别很难解决汉语中不同方言的问题,限制了它的使用区域;另外还有一个因素也应予以考虑,家电中用于控制的具体命令词语不要完全固定,应当根据的用户的习惯而改变,这一点在非特定人识别中几乎不可能实现。因此大多数家电遥控器不适合采用此方案。DP特定人识别的优点是方法简单,对硬件资源要求较低;此外,这一方法中的训练过程也很简单,不需预先采集过多的样本,不仅降低了前期成本,而且可以根据用户习惯,由用户任意定义控制项目的具体命令语句,因而适合大多数家电遥控器的应用。DP特定识别的严重缺点是它的稳健性不理想,对有些人的语音识别率高,有的人识别率却不高;刚训练完时识别率较高,但随着时间的推迟而识别率降低。些缺点往往给用户带来不便。为克服这些缺陷,对传统方法作为改进,使识别性能和稳健性都有显著的提高,取得令人满意的结果。 1.1 端点检测方法 影响孤立词识别性能的一个重要因素是端点检测准确性[4]。在10个英语数字的识别测试中,60毫秒的端点误差就使识别率下降3%。对于面向消费类应用的语音识别芯片系统,各种干扰因素更加复杂,使检测端点问题更加困难。为此,提出了称为FRED(Frame-based Readl_time Endpoint Detection)算法[3]的两级端点检测方案,提高端点检测的。级对输入语音信号,根据其能量和过零率的变化,进行简单的实时端点检测,以便去掉静音得到输入语音的时域范围,并且在此基础上进行频谱特征提取工作。第二级根据输入语音频谱的FFT分析结果,分别计算出高频、中频和低频段的能量分布特性,用来判别轻辅音、浊辅音和元音;在确定了元音、浊音段后,再向前后两端扩展搜索包含语音端点的帧。FRED端点检测算法根据语音的本质特征进行端点检测,可以更好地适应环境的干扰和变化,提高端点检测的。 在特定人识别中,比较了常用的FED(Fast Endpoint Detection)[5]和FRED两种端点检测算法的性能。两种算法测试使用相同的数据库,包括7个人的录音,每个人说100个人名,每个人名读3遍。测试中的DP模板训练和识别算法为传统的固定端点动态时间伸缩(DTW)模板匹配算法[4]。两种端点检测算法的识别率测试结果列在表1中。 表1 比较FED和FRED端点检测算法对DTW模板匹配识别率的影响 端点检测算法第1人第2人第3人第4人第5人第6人第7人平均 FED 92.5% 87% 92.6% 95.6% 96.2% 96.8% 100% 94.4% FRED 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 测试结果说明:使用FRED端点检测算法,所有说话人的识别率都有了不同程度的提高。因此,本系统采用这种两级端点检测方案。 1.2 模拟匹配算法 DTW是典型的DP特定人算法,为了克服自然语速的差异,用动态时间规整方法将模板特征序列和语音特征序列进行匹配,比较两者之间的失真,得出识别判决的依据。 假设存储的一个词条模板包括M帧倒谱特征R={r(m);m=1,2,∧,M};识别特征序列包括N帧倒谱特征T={t(n);n=1,2, ∧,N}。在r(i)和t(i)之间定义帧局部失真D(i,j),D(i,j)=|r(i)-t(i)| 2,通过动态规划过程,在搜索路径中找到累积失真的路径,即的匹配结果。采用对称形式DTW:
1 语音识别算法 目前,常以单片机(MCU)或DSP作炎硬件平台的实现消费类电子产品中的语音识别。这类语音识别主要为孤立词识别,它有两种实现方案:一种是基于隐含马尔科夫统计模型(HMM)框架的非特定人识别;另一种是基于动态规划(DP)原理的特定人识别。它们在应用上各有优缺点。HMM非特定人员的优点是用户无需经过训练,可以直接使用;并且具良好的稳定性(即对使用者而言,语音识别性能不会随着时间的延长而降低)。但非特定人语音识别也有其很难克服的缺陷。首先,使用该方法需要预先采集大量的语料库,以便训练出相应的识别模型,这就大大提高了应用此技术的前期成本;其次,非特定人语音识别很难解决汉语中不同方言的问题,限制了它的使用区域;另外还有一个因素也应予以考虑,家电中用于控制的具体命令词语不要完全固定,应当根据的用户的习惯而改变,这一点在非特定人识别中几乎不可能实现。因此大多数家电遥控器不适合采用此方案。DP特定人识别的优点是方法简单,对硬件资源要求较低;此外,这一方法中的训练过程也很简单,不需预先采集过多的样本,不仅降低了前期成本,而且可以根据用户习惯,由用户任意定义控制项目的具体命令语句,因而适合大多数家电遥控器的应用。DP特定识别的严重缺点是它的稳健性不理想,对有些人的语音识别率高,有的人识别率却不高;刚训练完时识别率较高,但随着时间的推迟而识别率降低。些缺点往往给用户带来不便。为克服这些缺陷,对传统方法作为改进,使识别性能和稳健性都有显著的提高,取得令人满意的结果。 1.1 端点检测方法 影响孤立词识别性能的一个重要因素是端点检测准确性[4]。在10个英语数字的识别测试中,60毫秒的端点误差就使识别率下降3%。对于面向消费类应用的语音识别芯片系统,各种干扰因素更加复杂,使检测端点问题更加困难。为此,提出了称为FRED(Frame-based Readl_time Endpoint Detection)算法[3]的两级端点检测方案,提高端点检测的。级对输入语音信号,根据其能量和过零率的变化,进行简单的实时端点检测,以便去掉静音得到输入语音的时域范围,并且在此基础上进行频谱特征提取工作。第二级根据输入语音频谱的FFT分析结果,分别计算出高频、中频和低频段的能量分布特性,用来判别轻辅音、浊辅音和元音;在确定了元音、浊音段后,再向前后两端扩展搜索包含语音端点的帧。FRED端点检测算法根据语音的本质特征进行端点检测,可以更好地适应环境的干扰和变化,提高端点检测的。 在特定人识别中,比较了常用的FED(Fast Endpoint Detection)[5]和FRED两种端点检测算法的性能。两种算法测试使用相同的数据库,包括7个人的录音,每个人说100个人名,每个人名读3遍。测试中的DP模板训练和识别算法为传统的固定端点动态时间伸缩(DTW)模板匹配算法[4]。两种端点检测算法的识别率测试结果列在表1中。 表1 比较FED和FRED端点检测算法对DTW模板匹配识别率的影响 端点检测算法第1人第2人第3人第4人第5人第6人第7人平均 FED 92.5% 87% 92.6% 95.6% 96.2% 96.8% 100% 94.4% FRED 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 测试结果说明:使用FRED端点检测算法,所有说话人的识别率都有了不同程度的提高。因此,本系统采用这种两级端点检测方案。 1.2 模拟匹配算法 DTW是典型的DP特定人算法,为了克服自然语速的差异,用动态时间规整方法将模板特征序列和语音特征序列进行匹配,比较两者之间的失真,得出识别判决的依据。 假设存储的一个词条模板包括M帧倒谱特征R={r(m);m=1,2,∧,M};识别特征序列包括N帧倒谱特征T={t(n);n=1,2, ∧,N}。在r(i)和t(i)之间定义帧局部失真D(i,j),D(i,j)=|r(i)-t(i)| 2,通过动态规划过程,在搜索路径中找到累积失真的路径,即的匹配结果。采用对称形式DTW:  其中S(i,j)是累积失真,D(i,j)是局部失真。 当动态规划过程计算到固定结点(N,M)时,可以计算出该模板动态匹配的归一化距离,识别结果即该归一化距离的模板词条:x=argmin{S(N,Mx)}。 为了提高DTW识别算法的识别性能和模板的稳健性,提出了双模板策略,即x=argmin{S(N,M2x)}。次输入的训练词条存储为个模板,第二次输入的相同训练词条存储为第二个模板,希望每个词条通过两个较稳健的模板来保持较高的识别性能。与上面测试相同,也利用7个人说的100个人名,每个人名含3遍的数据库,比较DTW单模板和双模板的性能差别,结果更在表2中。 表2 DTW不同模板数的识别率比较 DTW 第1人第2人第3人第4人第5人第6人第7人平均 单模板 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 双模板 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% 测试结果说明:通过存储两个模板,相当大地提高了DTW识别的性能,其稳健性也有很大的提高。因此,对特定人识别系统,采用DTW双模板是简单有效的策略。 综上所述,该嵌入式语音识别芯片系统采用了改进端点检测性能的FRED算法,12阶Mel频标倒谱参数(MFCC)作为特征参数,使用双模板训练识别策略。通过一系列测试,证明该系统对特定人的识别达到了很好的识别性能,完全可以满足家用电器中声控应用的要求。 2 语音控制遥控器设计 目前家用遥控器主要为按键式,并有两种类型:一种是固定码型,每个键对应一种或几种码型,都是生产厂家预先设定好的,用户不能更改;另一种是学习型,具有自我学习遥控码的功能,可由用户定义遥控器的每个键对应的码型,它能够将多种遥控器集于一身,用一个遥控器就可控制多个家电,又可以作为原配遥控器的备份。由于现代家电功能不断增加,上述两种遥控器都有按键过多,用户不易记住每个键的含义等问题。将语音识别技术应用于学习型遥控器,利用语音命令代替按者对命令的记忆和使用,同时省去了大量按键,缩小了遥控器的体积。
其中S(i,j)是累积失真,D(i,j)是局部失真。 当动态规划过程计算到固定结点(N,M)时,可以计算出该模板动态匹配的归一化距离,识别结果即该归一化距离的模板词条:x=argmin{S(N,Mx)}。 为了提高DTW识别算法的识别性能和模板的稳健性,提出了双模板策略,即x=argmin{S(N,M2x)}。次输入的训练词条存储为个模板,第二次输入的相同训练词条存储为第二个模板,希望每个词条通过两个较稳健的模板来保持较高的识别性能。与上面测试相同,也利用7个人说的100个人名,每个人名含3遍的数据库,比较DTW单模板和双模板的性能差别,结果更在表2中。 表2 DTW不同模板数的识别率比较 DTW 第1人第2人第3人第4人第5人第6人第7人平均 单模板 94.3% 89.9% 93.2% 99.4% 99.4% 98.8% 100% 96.4% 双模板 99.4% 96.6% 98.5% 100% 100% 98.8% 100% 99.0% 测试结果说明:通过存储两个模板,相当大地提高了DTW识别的性能,其稳健性也有很大的提高。因此,对特定人识别系统,采用DTW双模板是简单有效的策略。 综上所述,该嵌入式语音识别芯片系统采用了改进端点检测性能的FRED算法,12阶Mel频标倒谱参数(MFCC)作为特征参数,使用双模板训练识别策略。通过一系列测试,证明该系统对特定人的识别达到了很好的识别性能,完全可以满足家用电器中声控应用的要求。 2 语音控制遥控器设计 目前家用遥控器主要为按键式,并有两种类型:一种是固定码型,每个键对应一种或几种码型,都是生产厂家预先设定好的,用户不能更改;另一种是学习型,具有自我学习遥控码的功能,可由用户定义遥控器的每个键对应的码型,它能够将多种遥控器集于一身,用一个遥控器就可控制多个家电,又可以作为原配遥控器的备份。由于现代家电功能不断增加,上述两种遥控器都有按键过多,用户不易记住每个键的含义等问题。将语音识别技术应用于学习型遥控器,利用语音命令代替按者对命令的记忆和使用,同时省去了大量按键,缩小了遥控器的体积。 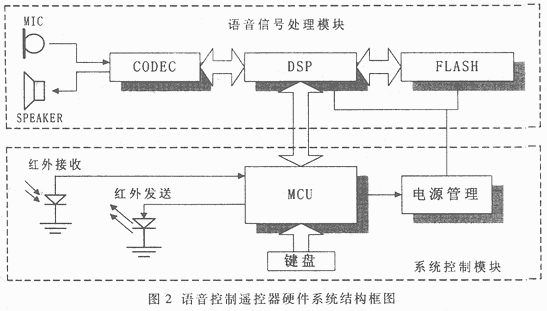 语音控制遥控器的硬件框图如图2所示,它由两个独立的模块组成:语音信号处理模块和系统控制模块。 语音信号算是模块由DSP、快闪存储器(FLASH)、编解码器(CODEC)组成。其中DSP是整个语音识别模块的,负责语音识别、语音编解码,以及FLASH的读写控制。DSP的优点是运算速度快、内存空间大、数据交换速度快,可用来实现复杂的算法,提高识别率,减小反应延时,得到较高的识别性能。DSP芯片选用Analog Devices公司的AD2186L,它具有如下特点:①运算速度达40MIPS,且均为高效的单调周期指令;②提供了40K字节的片内RAM,其中8K字(16Bit/字)为数据RAM,8K字(24Bit/字)为程序RAM,可达4兆字节的存储区,用于存储数据或程序;③3.3V工作电压,具有多种省电模式。AD2186L既能完成与语音信号算是相关的算法,又适合使用电池作能源的遥控器。FLASH和CODEC也都选用3.3V工作电压的芯片。FLASH为美国ATMEL公司的AT29LV040A(4M Bit),它作为系统的存储器,主要用于存放以下内容:提示语音合成所需的参数,特定人训练后的码本数据,DSP系统的应用程序和学习和遥控码数据。CODEC选用美国TI公司的TLV320AC37,用来进行A/D、D/A变换、编码和解码。 系统控制模块由单片机、红外接收发送器、电源管理电路组成。单片机负责整个遥控器的系统控制。单片机作为主控芯片,进行键盘扫描,根据用户通过键盘输入的指令,分别完成学习遥控码;控制DSP进行语音训练、回放、识别;将识别结果转换成相应的遥控码,通过红外发光管发射出去。单片机与DSP之间通过标准的RS232串行协议通讯。
语音控制遥控器的硬件框图如图2所示,它由两个独立的模块组成:语音信号处理模块和系统控制模块。 语音信号算是模块由DSP、快闪存储器(FLASH)、编解码器(CODEC)组成。其中DSP是整个语音识别模块的,负责语音识别、语音编解码,以及FLASH的读写控制。DSP的优点是运算速度快、内存空间大、数据交换速度快,可用来实现复杂的算法,提高识别率,减小反应延时,得到较高的识别性能。DSP芯片选用Analog Devices公司的AD2186L,它具有如下特点:①运算速度达40MIPS,且均为高效的单调周期指令;②提供了40K字节的片内RAM,其中8K字(16Bit/字)为数据RAM,8K字(24Bit/字)为程序RAM,可达4兆字节的存储区,用于存储数据或程序;③3.3V工作电压,具有多种省电模式。AD2186L既能完成与语音信号算是相关的算法,又适合使用电池作能源的遥控器。FLASH和CODEC也都选用3.3V工作电压的芯片。FLASH为美国ATMEL公司的AT29LV040A(4M Bit),它作为系统的存储器,主要用于存放以下内容:提示语音合成所需的参数,特定人训练后的码本数据,DSP系统的应用程序和学习和遥控码数据。CODEC选用美国TI公司的TLV320AC37,用来进行A/D、D/A变换、编码和解码。 系统控制模块由单片机、红外接收发送器、电源管理电路组成。单片机负责整个遥控器的系统控制。单片机作为主控芯片,进行键盘扫描,根据用户通过键盘输入的指令,分别完成学习遥控码;控制DSP进行语音训练、回放、识别;将识别结果转换成相应的遥控码,通过红外发光管发射出去。单片机与DSP之间通过标准的RS232串行协议通讯。  系统的控制软件流程图如图3所示。在使用前,按“学习键”进入学习状态,用户先对学习型遥控器训练语音命令,并使其学习与各语音命令相对应的原理控码型。使用时按“识别键”,进入语音识别状态,等待语音处理模块返回结果,若返回正确的识别结果,则把相应的遥控码发射出去。例如,原电视遥控器数字键“1”对应中央1台,用户的训练命令为“中央1台”,学习了原遥控器的数字键“1”的遥控码,并使其与训练命令“中央1台”对应起来。于是使用时只需对着学习型遥控器的麦克风说出“中央1台”,电视就会切换到中央1台。这样用户不需要记住每个电视台与台号的对应关系,相对于枯燥的频道数字,用户自定义的命令更容易记住。 若连续的30秒无正确的命令则遥控器进入休眠状态,单片机控制电源管理电路切换DSP和FLASH电源,单片机本身也进入休眠状态,直至用户按键,唤醒单片机,再由单片机控制恢复DSP和FLASH供电,重新开始工作。这是因为整个系统中,DSP的功耗,长时间不用时,关闭语音信号处理模块,可以显著地降低整个系统的功耗。 从实验室走向市场的过程中,可靠性与成本是遇到的挑战。采用双模板的DTW和两组端点检测FRED算法,可在系统资源和反应延时增加极小的情况下,有效地提高识别率和稳健性。该项技术成功地运用在学习型遥控器上,展现了语音识别技术在家电领域的广阔前景。
系统的控制软件流程图如图3所示。在使用前,按“学习键”进入学习状态,用户先对学习型遥控器训练语音命令,并使其学习与各语音命令相对应的原理控码型。使用时按“识别键”,进入语音识别状态,等待语音处理模块返回结果,若返回正确的识别结果,则把相应的遥控码发射出去。例如,原电视遥控器数字键“1”对应中央1台,用户的训练命令为“中央1台”,学习了原遥控器的数字键“1”的遥控码,并使其与训练命令“中央1台”对应起来。于是使用时只需对着学习型遥控器的麦克风说出“中央1台”,电视就会切换到中央1台。这样用户不需要记住每个电视台与台号的对应关系,相对于枯燥的频道数字,用户自定义的命令更容易记住。 若连续的30秒无正确的命令则遥控器进入休眠状态,单片机控制电源管理电路切换DSP和FLASH电源,单片机本身也进入休眠状态,直至用户按键,唤醒单片机,再由单片机控制恢复DSP和FLASH供电,重新开始工作。这是因为整个系统中,DSP的功耗,长时间不用时,关闭语音信号处理模块,可以显著地降低整个系统的功耗。 从实验室走向市场的过程中,可靠性与成本是遇到的挑战。采用双模板的DTW和两组端点检测FRED算法,可在系统资源和反应延时增加极小的情况下,有效地提高识别率和稳健性。该项技术成功地运用在学习型遥控器上,展现了语音识别技术在家电领域的广阔前景。 免责声明: 凡注明来源本网的所有作品,均为本网合法拥有版权或有权使用的作品,欢迎转载,注明出处。非本网作品均来自互联网,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。